
YOLOv8 リアルタイム物体検出1 (基礎)
YOLOv8 リアルタイム物体検出(基礎)
YOLO(You Only Look Once)は、2016 年に Joseph Redmon らによって提案されたワンステージ型の物体検出アルゴリズムです。従来の物体検出手法とは異なり、YOLO は画像全体を一度だけ評価して、直接物体の位置とクラスを予測します。この「一度だけ見る」というアプローチにより、極めて高速な処理速度を実現しています。
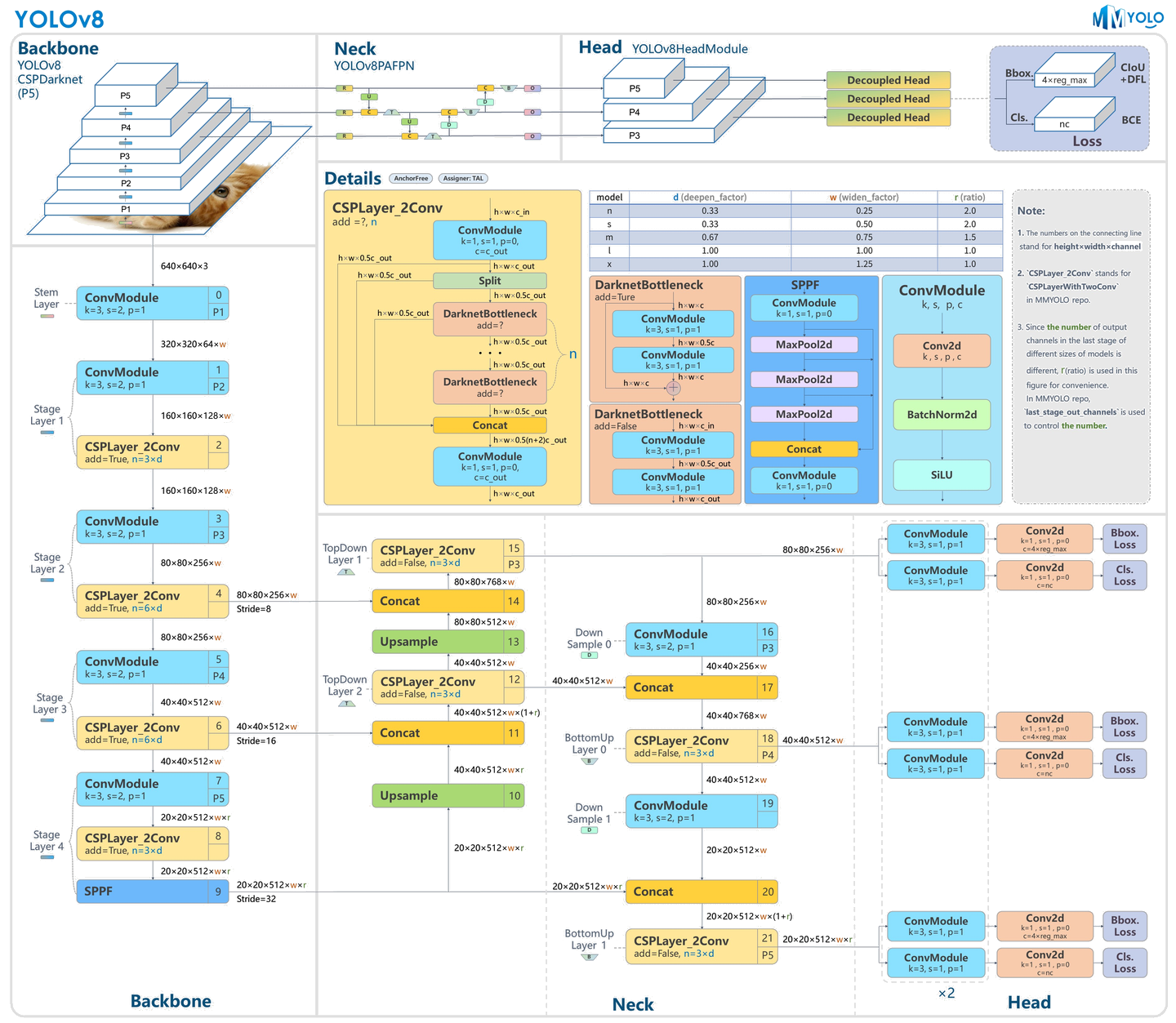
YOLOv8 のアーキテクチャは、主に以下の 3 つの部分で構成されています:
-
バックボーン(Backbone):入力画像から特徴量を抽出する役割を担います。YOLOv8 では、CSPDarknet をベースに改良された構造が採用されており、C2f モジュールによって効率的な特徴抽出を実現しています。
-
ネック(Neck):バックボーンで抽出された特徴量をさらに強化し、異なるスケールの特徴を統合します。PAN-FPN(Path Aggregation Network - Feature Pyramid Network)構造を用いることで、マルチスケールの物体検出性能を向上させています。
-
ヘッド(Head):最終的な物体の位置(バウンディングボックス)とクラス確率を予測します。YOLOv8 ではアンカーフリー方式が採用されており、事前に定義したアンカーボックスに依存せず、直接物体の中心座標と幅・高さを予測します。
基本モジュール
YOLOv8 のアーキテクチャは、いくつかの重要なモジュールによって構成されています。各モジュールの役割と、なぜこの構造が効果的なのかを詳しく見ていきましょう。
CBS (ConvModule)
CBS は YOLOv8 の最基本的な構成要素で、**Conv(畳み込み層)+ BN(バッチ正規化)+ SiLU(活性化関数)**の 3 つから構成されます。
データフロー:入力 → 畳み込み → バッチ正規化 → 活性化関数 → 出力
class Conv(nn.Module):
"""
標準畳み込み層
引数:入力チャネル (ch_in), 出力チャネル (ch_out), カーネルサイズ,ストライド,パディング,グループ,ダイレーション,活性化関数
"""
default_act = nn.SiLU() # デフォルトの活性化関数:SiLU(Sigmoid Linear Unit)
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""
畳み込み層の初期化
引数:
c1 (int): 入力テンソルのチャネル数
c2 (int): 出力テンソルのチャネル数
k (int): 畳み込みカーネルサイズ(デフォルト:1)
s (int): ストライド(デフォルト:1)
p (int): パディング(デフォルト:None, autopad で自動計算)
g (int): グループ数(デフォルト:1, 1 の場合は通常の畳み込み)
d (int): ダイレーション(膨張率,デフォルト:1)
act (bool or nn.Module): 活性化関数の有無またはモジュール(デフォルト:True)
"""
super().__init__()
# 2D 畳み込み層:バイアスは BN を使用するため不要
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
# バッチ正規化:学習の安定化と正則化効果
self.bn = nn.BatchNorm2d(c2)
# 活性化関数:True の場合はデフォルトの SiLU, Module の場合はそれを使用,それ以外は Identity
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""
順伝播処理
入力テンソルに対して、畳み込み→バッチ正規化→活性化関数の順で適用
引数:
x (Tensor): 入力テンソル [batch_size, c1, height, width]
戻り値:
Tensor: 活性化後の出力テンソル [batch_size, c2, new_height, new_width]
"""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""
融合済み順伝播処理
推論時に BN を畳み込み層に統合して高速化
引数:
x (Tensor): 入力テンソル
戻り値:
Tensor: 畳み込みと活性化を適用した出力
"""
return self.act(self.conv(x))
各成分の役割:
- Conv(畳み込み層):画像から特徴量を抽出します。カーネルサイズ(k)、ストライド(s)、パディング(p)などのパラメータで制御されます。
- BN(Batch Normalization):学習を安定させ、収束を早めます。また、過学習を防ぐ正則化の効果もあります。
- SiLU(Sigmoid Linear Unit):活性化関数で、ReLU の改良版です。負の領域でも勾配が流れやすく、平滑な活性化により最適化が容易になります。
Bottleneck (DarknetBottleneck)
Bottleneck は、**「チャネル数を減らして増やす」**という砂時計のような構造を持ちます。これにより、計算コストを抑えながら深いネットワークを構築できます。
データフロー:
- メインパス: 入力 → Conv1(チャネル削減)→ Conv2(チャネル復元)→ ショートカット判定 → 出力
- ショートカットパス: 入力 → (c1 == c2 の場合のみ)加算 → 出力
class Bottleneck(nn.Module):
"""
標準ボトルネック構造
チャネル数を一旦削減し、その後元に戻すことで、計算量を削減しながら深いネットワークを構築
"""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""
ボトルネックモジュールの初期化
引数:
c1 (int): 入力チャネル数
c2 (int): 出力チャネル数
shortcut (bool): 残差接続(ショートカット)の使用有無(デフォルト:True)
g (int): グループ数(デフォルト:1)
k (tuple): 2 つの畳み込み層のカーネルサイズ(デフォルト:(3, 3))
e (float): 拡張率(expansion ratio)。隠れチャネル数を計算(c2 * e)(デフォルト:0.5)
"""
super().__init__()
c_ = int(c2 * e) # 隠れチャネル数:出力チャネルの半分(e=0.5 の場合)
# 1 つ目の畳み込み層:チャネル数を削減(c1 → c_)
self.cv1 = Conv(c1, c_, k[0], 1)
# 2 つ目の畳み込み層:チャネル数を元に戻す(c_ → c2)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
# ショートカット接続の有効/無効:入力と出力のチャネル数が同じ場合のみ加算可能
self.add = shortcut and c1 == c2
def forward(self, x):
"""
順伝播処理
引数:
x (Tensor): 入力テンソル
戻り値:
Tensor: ボトルネック処理後の出力
ショートカットが有効なら入力 + 出力、無効なら出力のみ
"""
# ショートカット接続:x + F(x) (ResNet の残差ブロックと同様)
# これにより勾配消失問題を緩和し、深いネットワークの学習を可能にする
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
重要なポイント:
- チャネル圧縮:
e=0.5により、一旦チャネル数を半分に減らします(c_ = c2 * 0.5)。これにより計算量を削減。 - 2 段階の畳み込み:1 つ目の Conv でチャネルを減らし、2 つ目の Conv で元のチャネル数に戻します。
- ショートカット接続:
self.addが入力と出力を加算します(ResNet の残差接続と同様)。これにより勾配消失問題を緩和し、深いネットワークの学習を可能にします。
C2f (CSPLayer_2Conv)
C2f は YOLOv8 の核心的なモジュールで、CBS と Bottleneck を組み合わせた深いネットワーク構造です。CSP(Cross Stage Partial)構造を採用しています。
データフロー:
- 初期処理: 入力 → Conv1(c1 → 2×c)→ 分割(2 つのパス)
- 並列パス:
- パス 1: そのまま保持(skip connection)
- パス 2: n 個の Bottleneck を順次通過(各 Bottleneck: c → c)
- 特徴統合: すべてのパスを連結 → Conv2((2+n)×c → c2)→ 出力
例:n=3 の場合
- 入力: [batch, c1, H, W]
- Conv1 後: [batch, 2c, H, W]
- 分割後: 2 つの [batch, c, H, W]
- Bottleneck 3回: 3 つの [batch, c, H, W] が追加
- 連結前: 合計 5 つの特徴マップ(2 + 3)
- 連結後: [batch, 5c, H, W]
- 出力: [batch, c2, H, W]
class C2f(nn.Module):
"""
CSP ボトルネックの高速実装(2 つの畳み込み層)
Cross Stage Partial 構造を採用し、豊富な勾配フローを実現
YOLOv8 の中核となるモジュール
"""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""
CSP ボトルネック層の初期化
引数:
c1 (int): 入力チャネル数
c2 (int): 出力チャネル数
n (int): Bottleneck モジュールの数(デフォルト:1)
shortcut (bool): Bottleneck 内のショートカット接続の使用有無(デフォルト:False)
g (int): グループ数(デフォルト:1)
e (float): 拡張率(隠れチャネル数の計算に使用)(デフォルト:0.5)
"""
super().__init__()
self.c = int(c2 * e) # 隠れチャネル数:出力チャネルの半分
# 最初の畳み込み層:入力チャネルを 2 倍の隠れチャネル数に変換
# これにより後で 2 つのパスに分割可能に
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
# 最終畳み込み層:すべてのパスの特徴を連結した後、チャネル数を調整
# (2 + n) * self.c: 初期の 2 パス + n 個の Bottleneck 出力
self.cv2 = Conv((2 + n) * self.c, c2, 1) # オプション:act=FReLU(c2)
# Bottleneck モジュールのリスト:各 Bottleneck は同じチャネル数を維持
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""
C2f 層の順伝播処理
特徴マップを分割→複数のパスを通す→連結することで、
異なる深さの特徴を同時に保持し、豊かな勾配フローを実現
引数:
x (Tensor): 入力テンソル
戻り値:
Tensor: C2f 処理後の出力テンソル
"""
# ステップ 1: 最初の畳み込みで特徴マップを 2 つに分割
# chunk(2, 1) はチャネル方向(dim=1)に等分する
y = list(self.cv1(x).chunk(2, 1))
# ステップ 2: 各 Bottleneck を順に適用
# y[-1](直前の出力)を次の Bottleneck に入力
# extend でリストに要素を追加し、すべての特徴を保持
# これにより、異なる深さの特徴量がすべて保存される
y.extend(m(y[-1]) for m in self.m)
# ステップ 3: すべての特徴をチャネル方向に連結し、最終畳み込みで次元を調整
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""
split() を使用した順伝播処理(chunk の代わりに実装)
機能的には forward と同等だが、split メソッドを使用
引数:
x (Tensor): 入力テンソル
戻り値:
Tensor: C2f 処理後の出力テンソル
"""
# split((self.c, self.c), 1) で明示的にチャネルを分割
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
C2f の仕組みと利点:
-
特徴マップの分割:
self.cv1(x).chunk(2, 1)で入力特徴マップを 2 つに分割します。- 一方はそのまま、もう一方は複数の Bottleneck レイヤを通します。
-
マルチスケール特徴の統合:
y.extend(m(y[-1]) for m in self.m)で、Bottleneck を順に適用し、各段階の特徴を保持します。- これにより、異なる深さの特徴量がすべて保存されます。
-
豊かな勾配フロー:
- 複数のパスを通じて勾配が流れるため、効率的な学習が可能になります。
- CSP 構造により、計算コストを抑えながら表現力を向上させます。
-
なぜ C2f が効果的か:
- 特徴の多様性:複数の Bottleneck を通じることで、様々な抽象度の特徴を同時に保持できます。
- 効率的な計算:チャネル数を調整することで、計算量を増やさずに深いネットワークを実現。
- 勾配の流れの改善:複数のパスがあることで、バックプロパゲーション時に勾配が効率的に伝わります。
SPPF (Spatial Pyramid Pooling - Fast)
SPPF は、異なるスケールの特徴を効率的に抽出するためのレイヤです。YOLOv5 から継承され、YOLOv8 でも引き続き採用されています。
データフロー:
- 初期処理: 入力 → Conv1(c1 → c_)→ 特徴マップ生成
- 逐次プーリング:
- 特徴 0: 元の特徵(受容野:1×1)
- 特徴 1: MaxPool 1回(受容野:5×5)
- 特徴 2: MaxPool 2回(受容野:9×9)
- 特徴 3: MaxPool 3回(受容野:13×13)
- 特徴統合: 4 つの特徴を連結 → Conv2(4×c_ → c2)→ 出力
受容野の計算原理:
- 各 MaxPool2d: kernel=5, stride=1, padding=2
- 1 回目: 5×5
- 2 回目: 5 + 5 - 1 = 9×9
- 3 回目: 9 + 5 - 1 = 13×13
- これにより SPP(k=(5, 9, 13)) と同等の効果を実現
class SPPF(nn.Module):
"""
空間ピラミッドプーリング - 高速版(SPPF)
YOLOv5 によって導入され、YOLOv8 でも継承されている
異なるスケールの特徴を効率的に抽出するためのレイヤ
"""
def __init__(self, c1, c2, k=5):
"""
SPPF 層の初期化
引数:
c1 (int): 入力チャネル数
c2 (int): 出力チャネル数
k (int): 最大プーリングのカーネルサイズ(デフォルト:5)
これにより SPP(k=(5, 9, 13)) と同等の受容野を実現
"""
super().__init__()
c_ = c1 // 2 # 隠れチャネル数:入力チャネルの半分
# 最初の畳み込み層:チャネル数を半分に削減
self.cv1 = Conv(c1, c_, 1, 1)
# 最終畳み込み層:連結された特徴(4 倍のチャネル)を出力チャネル数に変換
self.cv2 = Conv(c_ * 4, c2, 1, 1)
# 最大プーリング層:カーネルサイズ 5、ストライド 1、パディングは自動計算
# ストライド 1 なので特徴マップのサイズは変化しない
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""
SPPF 層の順伝播処理
逐次的な最大プーリングにより、複数の受容野を持つ特徴を生成
元の特徵と 3 つのプール特徵を連結することで、マルチスケール情報を保持
引数:
x (Tensor): 入力テンソル
戻り値:
Tensor: SPPF 処理後の出力テンソル
"""
# ステップ 1: 最初の畳み込みを適用
y = [self.cv1(x)]
# ステップ 2: 3 回の最大プーリングを逐次適用
# 1 回目:カーネル 5×5 の受容野
# 2 回目:累積で 9×9 の受容野(5+5-1)
# 3 回目:累積で 13×13 の受容野(9+5-1)
# それぞれの結果をリストに追加
y.extend(self.m(y[-1]) for _ in range(3))
# ステップ 3: 4 つの特徴(元 +3 つのプール)をチャネル方向に連結
# チャネル数:c_ * 4
# これにより、異なるスケールの局所的特徴と大域的特徴を同時に保持
return self.cv2(torch.cat(y, 1))
SPPF の動作原理:
-
逐次的な最大プーリング:
self.m(y[-1])を 3 回繰り返し適用します。- 1 回目:カーネルサイズ 5×5 のプール
- 2 回目:実質的に 9×9 の受容野
- 3 回目:実質的に 13×13 の受容野
-
特徴の連結:
- 元の特征と 3 つのプールされた特徴を連結します(合計 4 つ)。
- これにより、複数のスケールの特徴情報を保持できます。
-
なぜ SPPF が効果的か:
- マルチスケール対応:様々なサイズの物体を検出可能です。
- 受容野の拡大:大きなカーネルを使わずに、広い受容野を獲得できます。
- 計算効率:連続したプーリング操作は計算コストが低く、リアルタイム処理に適しています。
- 等価性:
SPP(k=(5, 9, 13))と同等の機能を、より効率的に実現しています。
なぜこのアーキテクチャが機能するのか
YOLOv8 のアーキテクチャが優れた性能を発揮する理由は、効率的な特徴抽出、勾配フローの最適化、マルチスケール特徴の統合、そして計算効率と精度のバランスという 4 つの設計思想にあります。まず、CBS、Bottleneck、C2f によって階層的に豊富な特徴を抽出でき、各モジュールが役割分担して計算リソースを効率的に活用しています。さらに、ショートカット接続(Bottleneck の self.add)により深いネットワークでも勾配消失を防ぎ、C2f の並列構造によって複数の勾配パスを確保することで、効率的な学習を実現しています。また、SPPF や後続の FPN/PAN 構造により様々なサイズの物体に対応可能で、細かい特徴と大域的な特徴を両方活用できます。加えて、チャネル圧縮(Bottleneck、C2f)により計算量を削減しながら表現力を維持し、リアルタイム処理と高精度検出の両立を実現している点が YOLOv8 の大きな特徴です。