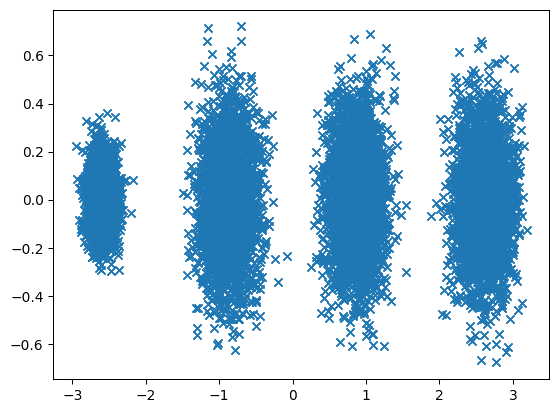数学基礎
固有値と固有ベクトル
もしベクトルv v v A A A
A v = λ v Av=\lambda v
A v = λ v
ここで:
λ λ λ v v v 固有値 ある行列の固有ベクトルの組は直交ベクトル の組です
重要な性質
固有ベクトルは行列の変換に対して方向を変えない(スカラー倍されるだけ)
固有値はその方向における変換の「伸縮率」を表す
固有値分解行列
行列A A A v v v A A A
A = Q Σ Q − 1 A=Q\Sigma Q^{-1}
A = Q Σ Q − 1
ここで:
Q Q Q A A A Σ \Sigma Σ
実対称行列の場合
実対称行列(例えば共分散行列)の場合、Q Q Q Q − 1 = Q T Q^{-1} = Q^T Q − 1 = Q T
A = Q Σ Q T A=Q\Sigma Q^T
A = Q Σ Q T
PCAとの関係
PCAでは、共分散行列の固有値分解を行い、最大の固有値に対応する固有ベクトル(主成分)を選択
固有値の大きさは、その主成分方向のデータの分散の大きさを示す
固有ベクトルは主成分の方向を表す
基底変換
数式表現
Y = P X = [ p 1 p 2 ⋮ p r ] r × n [ x 1 x 2 ⋯ x m ] n × m = [ p 1 x 1 p 1 x 2 ⋯ p 1 x m p 2 x 1 p 2 x 2 ⋯ p 2 x m ⋮ ⋮ ⋱ ⋮ p r x 1 p r x 2 ⋯ p r x m ] r × m Y = PX = \begin{bmatrix}
p_1 \\
p_2 \\
\vdots \\
p_r
\end{bmatrix}_{r\times n}[
\begin{array}
{cccccc}x_1 & x_2 & \cdots & x_m
\end{array}]_{n\times m}=
\begin{bmatrix}
p_1x_1 & p_1x_2 & \cdots & p_1x_m \\
p_2x_1 & p_2x_2 & \cdots & p_2x_m \\
\vdots & \vdots & \ddots & \vdots \\
p_rx_1 & p_rx_2 & \cdots & p_rx_m
\end{bmatrix}_{r\times m}
Y = P X = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ p 1 p 2 ⋮ p r ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ r × n [ x 1 x 2 ⋯ x m ] n × m = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ p 1 x 1 p 2 x 1 ⋮ p r x 1 p 1 x 2 p 2 x 2 ⋮ p r x 2 ⋯ ⋯ ⋱ ⋯ p 1 x m p 2 x m ⋮ p r x m ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ r × m
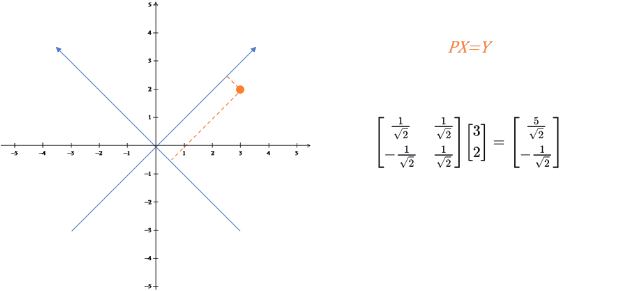
元の基底:$ {[p_1, p_2, …, p_n]}^T $
新しい基底:$ {[x_1, x_2, …, x_m]} $
座標変換:$ P $ が旧座標系でのベクトル、$ x $ が新座標系でのベクトルなら、$ Y = PX $
本質
行列掛け算の本質は基底変換 である。
基底変換と座標系の伸長と回転
座標系の伸長
Y = X P Y = XP
Y = X P
P = [ a 0 0 b ] P = \begin{bmatrix} a & 0 \\ 0 & b \end{bmatrix}
P = [ a 0 0 b ]
例
X = [ 1 2 3 4 ] , P = [ 2 0 0 0.5 ] X = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix}, \quad P = \begin{bmatrix} 2 & 0 \\ 0 & 0.5 \end{bmatrix}
X = [ 1 3 2 4 ] , P = [ 2 0 0 0 . 5 ]
Y = X P = [ 1 2 3 4 ] [ 2 0 0 0.5 ] = [ 2 1 6 2 ] Y = XP = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} \begin{bmatrix} 2 & 0 \\ 0 & 0.5 \end{bmatrix} = \begin{bmatrix} 2 & 1 \\ 6 & 2 \end{bmatrix}
Y = X P = [ 1 3 2 4 ] [ 2 0 0 0 . 5 ] = [ 2 6 1 2 ]
この例では、第1特徴量を2倍に伸長し、第2特徴量を0.5倍に縮小しています。
座標系の回転
Y = R X Y = RX
Y = R X
R = [ c o s ( θ ) − s i n ( θ ) s i n ( θ ) c o s ( θ ) ] R = \begin{bmatrix} cos(\theta) & -sin(\theta) \\ sin(\theta) & cos(\theta) \end{bmatrix}
R = [ c o s ( θ ) s i n ( θ ) − s i n ( θ ) c o s ( θ ) ]
分散
分散は数値が平均値からどれだけ散らばっているかを示す指標です。
数式:
Var ( X ) = 1 n ∑ i = 1 n ( x i − x ˉ ) 2 \text{Var}(X) = \frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})^2
Var ( X ) = n 1 i = 1 ∑ n ( x i − x ˉ ) 2
ここで:
$ x_i $:個々のデータ点
$ \bar{x} $:データの平均
$ n $:データ点の数
共分散
共分散は2つの変数が一緒にどう変化するかを測る指標で、同時に増加する傾向があるかを示します。
数式
Cov ( X , Y ) = 1 n ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) \text{Cov}(X,Y) = \frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})
Cov ( X , Y ) = n 1 i = 1 ∑ n ( x i − x ˉ ) ( y i − y ˉ )
ここで:
$ x_i, y_i $:2つの異なる変数のデータ点
$ \bar{x}, \bar{y} $:それぞれの変数の平均
解釈:
正の共分散:変数が一緒に増加する傾向
負の共分散:一方が増えると他方は減る
ゼロの共分散:線形関係なし
本質:共分散行列は、各変数の共分散を対角要素として持つ矩形行列です、共分散は 0 0 0
共分散行列
共分散行列は多変量データセットの各次元ペア間の共分散を含む正方行列です。
数式
先ず要するに、行列X n × m X_{n \times m} X n × m
C = 1 m − 1 X X T C=\frac{1}{m-1} XX^T
C = m − 1 1 X X T
手順は以下通り:
サンプル平均
x ˉ = 1 n ∑ i = 1 N x i \bar{x}=\frac{1}{n}\sum_{i=1}^{N}{x_{i}}
x ˉ = n 1 i = 1 ∑ N x i
サンプル分散
V a r ( x ) = S 2 = 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) 2 Var(x)=S^{2}=\frac{1}{n-1}\sum_{i=1}^{n}{\left( x_{i}-\bar{x} \right)^2}
V a r ( x ) = S 2 = n − 1 1 i = 1 ∑ n ( x i − x ˉ ) 2
サンプルの共分散
C o v ( x , y ) = 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) Cov(x,y)=\frac{1}{n-1}\sum_{i=1}^{n}{\left( x_{i}-\bar{x} \right)\left( y_{i}-\bar{y} \right)}
C o v ( x , y ) = n − 1 1 i = 1 ∑ n ( x i − x ˉ ) ( y i − y ˉ )
サンプルの共分散行列
ここで、d i m = 2 dim=2 d i m = 2 [ x , y ] T {[x,y]}^T [ x , y ] T
C = [ V a r ( x ) C o v ( x , y ) C o v ( x , y ) V a r ( y ) ] C=
\begin{bmatrix}
Var(x) & Cov(x,y) \\
Cov(x,y) & Var(y)
\end{bmatrix}
C = [ V a r ( x ) C o v ( x , y ) C o v ( x , y ) V a r ( y ) ]
d i m = n dim=n d i m = n [ x 1 , x 2 , . . . , x n ] T {[x_1,x_2,...,x_n]}^T [ x 1 , x 2 , . . . , x n ] T
C = [ V a r ( x 1 ) C o v ( x 1 , x 2 ) ⋯ C o v ( x 1 , x n ) C o v ( x 2 , x 1 ) V a r ( x 2 ) ⋯ C o v ( x 1 , x n ) ⋮ ⋮ ⋱ ⋮ C o v ( x n , x 1 ) C o v ( x n , x 2 ) ⋯ V a r ( x n ) ] C=
\begin{bmatrix}
Var(x_1) & Cov(x_1,x_2) & \cdots & Cov(x_1,x_n) \\
Cov(x_2,x_1) & Var(x_2) & \cdots & Cov(x_1,x_n) \\
\vdots & \vdots & \ddots & \vdots \\
Cov(x_n,x_1) & Cov(x_n,x_2) & \cdots & Var(x_n)
\end{bmatrix}
C = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ V a r ( x 1 ) C o v ( x 2 , x 1 ) ⋮ C o v ( x n , x 1 ) C o v ( x 1 , x 2 ) V a r ( x 2 ) ⋮ C o v ( x n , x 2 ) ⋯ ⋯ ⋱ ⋯ C o v ( x 1 , x n ) C o v ( x 1 , x n ) ⋮ V a r ( x n ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎤
SVD
SVDの定義
特異値分解は、任意の行列に適用可能な分解方法であり、任意の行列Aに対して常に特異値分解が存在します。
数式表現
A = U Σ V T A = U \Sigma V^T
A = U Σ V T
ここで:
A :m × n m \times n m × n U :m × m m \times m m × m Σ :m × n m \times n m × n V^T :n × n n \times n n × n
SVD分解の手順
A A T AA^T A A T
A A T AA^T A A T 固有ベクトルを正規化して行列 U を構成
A T A A^TA A T A
A T A A^TA A T A 固有ベクトルを正規化して行列 V を構成
特異値の計算
A A T AA^T A A T A T A A^TA A T A その値を対角要素として行列 Σ を構成
重要な特徴
特異値 は通常、大きい順に並べられますU は左特異ベクトル(A A T AA^T A A T V は右特異ベクトル(A T A A^TA A T A Σ の対角要素が特異値であり、行列Aの「重要度」を示します
PCA
PCA(主成分分析)は主成分を抽出するための手法である。主成分はデータの分散を最大にするベクトルである。
共分散行列対角化
ここで、二つの行列Y r × m Y_{r \times m} Y r × m X n × m X_{n \times m} X n × m
そして、
P r × n P_{r \times n} P r × n C C C X X X D D D Y Y Y
目的: 元のデータ X X X Y Y Y D D D 0 0 0
では、C C C D D D
D = 1 m Y Y T = 1 m ( P X ) ( P X ) T = 1 m P X X T P T = 1 m P ( X X T ) P T = P C P T = P [ 1 m ∑ i = 1 m x 1 i 2 1 m ∑ i = 1 m x 1 i x 2 i 1 m ∑ i = 1 m x 2 i x 1 i 1 m ∑ i = 1 m x 2 i 2 ] P T D
= \frac{1}{m}YY^T \\
= \frac{1}{m}(PX)(PX)^T \\
= \frac{1}{m}PXX^TP^T \\
= \frac{1}{m}P(XX^T)P^T \\
= PCP^T \\
= P \begin{bmatrix} \frac{1}{m}\sum_{i=1}^{m} x_{1i}^2 & \frac{1}{m}\sum_{i=1}^{m} x_{1i}x_{2i} \\ \frac{1}{m}\sum_{i=1}^{m} x_{2i}x_{1i} & \frac{1}{m}\sum_{i=1}^{m} x_{2i}^2 \end{bmatrix} P^T
D = m 1 Y Y T = m 1 ( P X ) ( P X ) T = m 1 P X X T P T = m 1 P ( X X T ) P T = P C P T = P [ m 1 ∑ i = 1 m x 1 i 2 m 1 ∑ i = 1 m x 2 i x 1 i m 1 ∑ i = 1 m x 1 i x 2 i m 1 ∑ i = 1 m x 2 i 2 ] P T
ここに計算するところ、求めている P P P P P P
言い換えれば、最適化目標は行列 P P P P C P T P C P^T P C P T P P P r r r P P P r r r X X X X X X n n n r r r
ここで最後に、共分散行列の対角化という問題に集中することになります。
上記より、X X X C C C
実対称行列の異なる固有値に対応する固有ベクトルは必ず直交する。
固有ベクトル λ i λ_i λ i k i k_i k i k i k_i k i
上記2つの性質より、n × n n \times n n × n n n n e 1 , e 2 , . . . , e n e_1, e_2, ..., e_n e 1 , e 2 , . . . , e n
E = [ e 1 , e 2 , . . . , e n ] E = [e_1, e_2, ..., e_n]
E = [ e 1 , e 2 , . . . , e n ]
xの共分散行列 C C C
E T C E = Λ = [ λ 1 0 0 . . . 0 0 λ 2 0 . . . 0 0 0 λ 3 . . . 0 0 0 0 . . . 0 0 0 0 . . . λ n ] E^TCE = \Lambda = \begin{bmatrix}
\lambda_1 & 0 & 0 & ... & 0 \\
0 & \lambda_2 & 0 & ... & 0 \\
0 & 0 & \lambda_3 & ... & 0 \\
0 & 0 & 0 & ... & 0 \\
0 & 0 & 0 & ... & \lambda_n
\end{bmatrix}
E T C E = Λ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ λ 1 0 0 0 0 0 λ 2 0 0 0 0 0 λ 3 0 0 . . . . . . . . . . . . . . . 0 0 0 0 λ n ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤
ここで、Λ \Lambda Λ
上記の式より:
D = P C P T D=P C P^T
D = P C P T
D D D
P = E T P = E^T
P = E T
は共分散行列の固有ベクトルを単位化して行方向に並べた行列で、各行は C C C P P P Λ \Lambda Λ P P P r r r X X X Y Y Y
固有値分解による共分散行列のPCA実装
入力
データセット X = { x 1 , x 2 , x 3 , . . . , x n } X=\left\{ x_{1},x_{2},x_{3},...,x_{n} \right\} X = { x 1 , x 2 , x 3 , . . . , x n }
手順
平均値の除去 (中心化):各特徴量からそれぞれの平均値を引く
共分散行列の計算 :1 n X X T \frac{1}{n}XX^T n 1 X X T
固有値分解 :共分散行列 1 n X X T \frac{1}{n}XX^T n 1 X X T
ソートと選択 :固有値を大きい順に並べ替え、最大のk個を選ぶ。対応するk個の固有ベクトルを行ベクトルとして構成される行列Pを得る
変換 :データをk個の固有ベクトルで構築された新しい空間に変換する:Y = P X Y=PX Y = P X
例
X = ( − 1 − 1 0 2 0 − 2 0 0 1 1 ) X=\left( \begin{matrix} -1 & -1 &0&2&0\\ -2&0&0&1&1 \end{matrix} \right)
X = ( − 1 − 2 − 1 0 0 0 2 1 0 1 )
この2行のデータを1行に削減するPCAの例:
X行列の各行はすでにゼロ平均であるため、平均値の除去は不要
共分散行列の計算:
C = 1 5 ( − 1 − 1 0 2 0 − 2 0 0 1 1 ) ( − 1 − 2 − 1 0 0 0 2 1 0 1 ) = ( 6 5 4 5 4 5 6 5 ) C=\frac{1}{5}\left( \begin{matrix} -1&-1&0&2&0\\ -2&0&0&1&1 \end{matrix} \right) \left( \begin{matrix} -1&-2\\ -1&0\\ 0&0\\ 2&1\\ 0&1 \end{matrix} \right) = \left( \begin{matrix} \frac{6}{5}&\frac{4}{5}\\ \frac{4}{5}&\frac{6}{5} \end{matrix} \right)
C = 5 1 ( − 1 − 2 − 1 0 0 0 2 1 0 1 ) ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ − 1 − 1 0 2 0 − 2 0 0 1 1 ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞ = ( 5 6 5 4 5 4 5 6 )
共分散行列の固有値と固有ベクトルの計算:
固有値:λ 1 = 2 \lambda_{1}=2 λ 1 = 2 λ 2 = 2 5 \lambda_{2}=\frac{2}{5} λ 2 = 5 2
固有ベクトル:c 1 ( 1 1 ) c_{1} \left( \begin{matrix} 1\\ 1 \end{matrix} \right) c 1 ( 1 1 ) c 2 ( − 1 1 ) c_{2} \left( \begin{matrix} -1\\ 1 \end{matrix} \right) c 2 ( − 1 1 )
標準化された固有ベクトル:( 1 2 1 2 ) \left( \begin{matrix} \frac{1}{\sqrt{2}}\\ \frac{1}{\sqrt{2}} \end{matrix} \right) ( 2 1 2 1 ) ( − 1 2 1 2 ) \left( \begin{matrix} -\frac{1}{\sqrt{2}}\\ \frac{1}{\sqrt{2}} \end{matrix} \right) ( − 2 1 2 1 )
行列P:
P = ( 1 2 1 2 − 1 2 1 2 ) P=\left( \begin{matrix} \frac{1}{\sqrt{2}}&\frac{1}{\sqrt{2}}\\ -\frac{1}{\sqrt{2}}&\frac{1}{\sqrt{2}}\\ \end{matrix} \right)
P = ( 2 1 − 2 1 2 1 2 1 )
最後にPの1行目でデータ行列Xを乗じて、次元削減された結果を得る:
Y = ( 1 2 1 2 ) ( − 1 − 1 0 2 0 − 2 0 0 1 1 ) = ( − 3 2 − 1 2 0 3 2 − 1 2 ) Y=\left( \begin{matrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{matrix} \right) \left( \begin{matrix} -1 & -1& 0&2&0\\ -2&0&0&1&1 \end{matrix} \right) = \left( \begin{matrix} -\frac{3}{\sqrt{2}} & - \frac{1}{\sqrt{2}} &0&\frac{3}{\sqrt{2}} & -\frac{1}{\sqrt{2}} \end{matrix} \right)
Y = ( 2 1 2 1 ) ( − 1 − 2 − 1 0 0 0 2 1 0 1 ) = ( − 2 3 − 2 1 0 2 3 − 2 1 )
注意 :固有値分解による共分散行列の方法では、データ行列Xの行(または列)方向の1つのPCA削減方向しか得られない。
SVD分解による共分散行列のPCA実装
入力
データセット X = { x 1 , x 2 , x 3 , . . . , x n } X=\left\{ x_{1},x_{2},x_{3},...,x_{n} \right\} X = { x 1 , x 2 , x 3 , . . . , x n }
手順
平均値の除去 :各特徴量からそれぞれの平均値を引く
共分散行列の計算
SVDによる固有値と固有ベクトルの計算
ソートと選択 :固有値を大きい順に並べ替え、最大のk個を選ぶ。対応するk個の固有ベクトルを列ベクトルとして構成される行列を得る
変換 :データをk個の固有ベクトルで構築された新しい空間に変換する
SVDの利点
PCA削減では、サンプル共分散行列 X X T XX^T X X T X X T XX^T X X T
SVD分解でPCAを実装する場合の2つの利点:
計算効率 :一部のSVD実装アルゴリズムでは、共分散行列 X X T XX^T X X T
双方向のPCA削減 :PCAではSVDの左特異行列のみを使用し、右特異行列は使用しないが、右特異行列にも用途がある。
m × n m \times n m × n X T X X^TX X T X k × n k \times n k × n V T V^T V T
X m × k ′ = X m × n V n × k T X_{m \times k}^{'}=X_{m \times n}V_{n \times k}^{T}
X m × k ′ = X m × n V n × k T
m × k m \times k m × k m × n m \times n m × n
PCAの本質
なお、PCAの目的を考え、“元のデータ X X X Y Y Y D D D 0 0 0 0 0 0 Y Y Y { y 1 , y 2 , . . . , y n } \{y_1, y_2,...,y_n\} { y 1 , y 2 , . . . , y n }
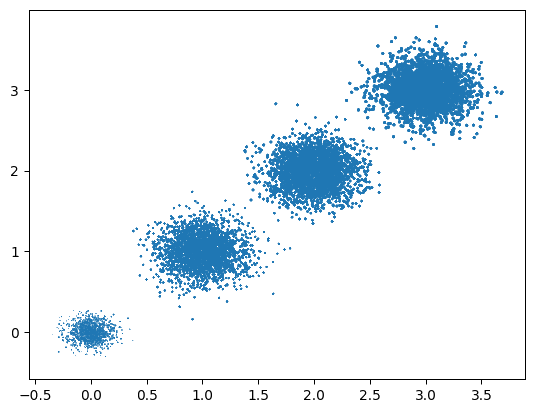
PCA前のデータ
PCA後のデータ
任意のデータ投影の第1の分散が第1座標(第1主成分)に来る
第2の分散が第2座標(第2主成分)に来る
Y = P X Y = PX Y = P X
コード
code