
MobileNetシリーズの説明
深度方向分離畳み込み
MobileNetV1の核心的な概念は、従来の標準的な畳み込みの代わりに深度方向分離畳み込みを使用することです。標準的な畳み込み操作は、入力特徴マップの空間次元(幅と高さ)とチャネル次元の両方に対して同時に情報抽出を行いますが、これは計算コストが非常に高くなります。深度方向分離畳み込みは、このプロセスを巧妙に2つのステップに分割します。
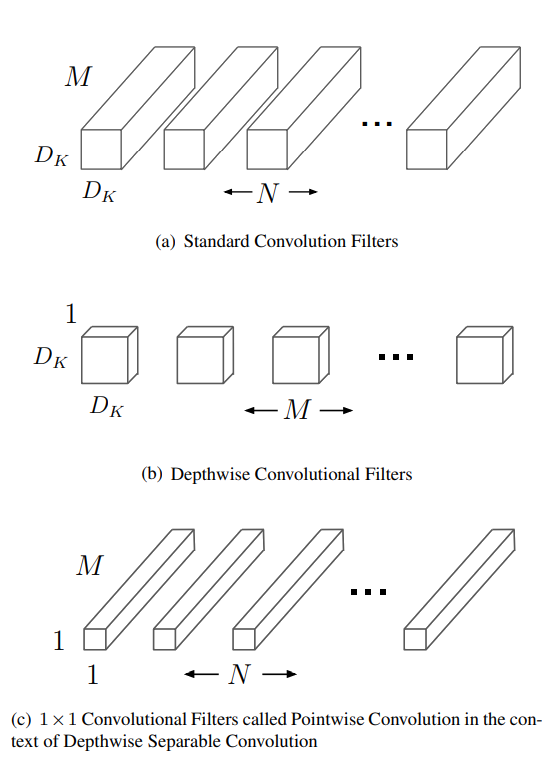
核心的な概念:2段階の分解
深度方向畳み込み (Depthwise Convolution)
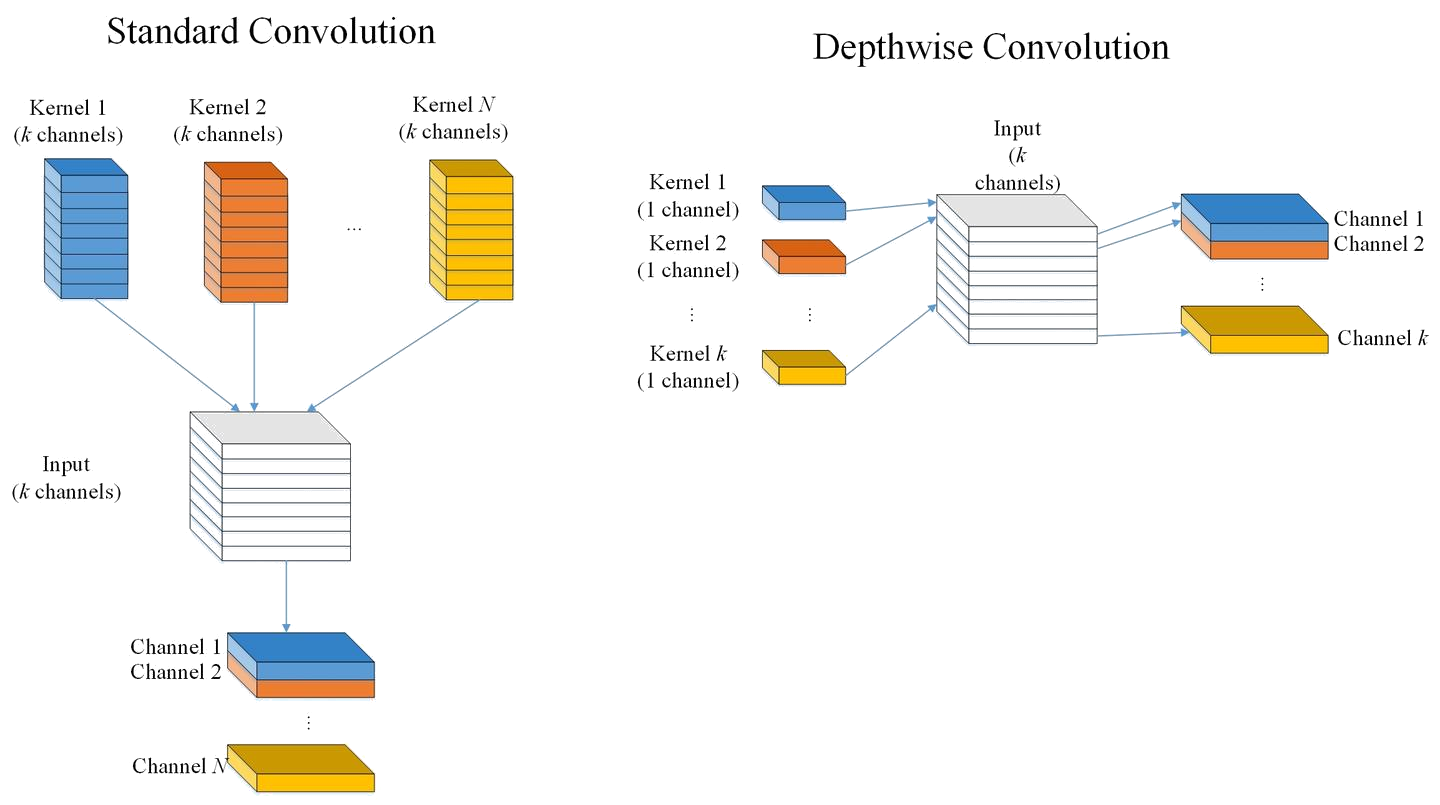
第一段階は深度方向畳み込みです。これは「空間フィルタリング」を担当し、入力の各チャネルに対して独立して1つの畳み込みカーネルを使用します。入力にM個のチャネルがあると仮定すると、深度方向畳み込みはM個の畳み込みカーネルを使用し、各カーネルは対応するチャネルのみを処理します。このステップでは特徴マップのサイズのみが変更され(stride>1またはpaddingがある場合)、チャネル数は変更されません。
ポイントワイズ畳み込み (Pointwise Convolution)
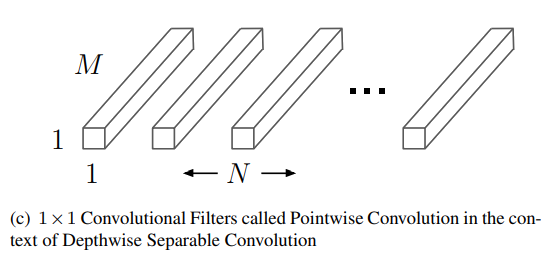
第二段階はポイントワイズ畳み込みです。これは「チャネルの組み合わせ」を担当し、本質的には1x1の標準的な畳み込みです。前のステップで各チャネルの情報は独立して処理されるため、チャネル間の交流はありません。ポイントワイズ畳み込みの役割は、1x1の畳み込みカーネルを使用して、前の深度方向畳み込みの出力であるM個のチャネルの特徴マップを重み付けして組み合わせ、新しい特徴を生成することです。このステップでは特徴マップのサイズは変更されず、チャネル数のみが変更されます。
Pointwise Convolutionの二つの役割
ポイントワイズ畳み込み(Pointwise Convolution)は実際には1×1畳み込みであり、DSC(深度方向分離畳み込み)において二つの重要な役割を果たします。
第一の役割:出力チャネル数の自由な変更
単独の深度方向畳み込みでは出力チャネル数を変更できないため、1×1畳み込みを用いて出力チャネル数を変更することは直感的で簡単な方法です。
第二の役割:チャネル融合
深度方向畳み込みのみを使用してネットワークを構築した場合の問題を理解するために、以下のようなシナリオを考えてみましょう:
- 入力をとし、その第iチャネルをとする
- 第一層の深度方向畳み込みの出力をとし、その第チャネルをとする
- 第二層の深度方向畳み込みの出力をとし、その第チャネルをとする
深度方向畳み込みの動作原理により:
- はのみに関連
- はのみに関連
- 結果として、ものみに関連
つまり、入力と出力の各チャネル間には何の計算的関連も存在しません。畳み込みはチャネル融合能力を持っているため、深度方向畳み込みの後にポイントワイズ畳み込みを接続することで、この問題を効果的に解決できます。
数式解析と計算複雑度の比較
以下の仮定に基づいて分析します:
- 入力特徴マップのサイズ:
- 畳み込みカーネルのサイズ:、その数:
標準的な畳み込み (Standard Convolution)
単一の畳み込みに対する計算量:
これは特徴マップの空間次元に含まれる個の点と、各点での畳み込み操作の計算量の積です。
個の畳み込みに対する総計算量:
ここで:
- :入力特徴マップのサイズ
- :カーネルのサイズ
- :入力特徴マップのチャネル数
- :カーネル数
深度方向分離畳み込み (DSC / Depthwise Separable Convolution)
深度方向畳み込みの計算総量:
ポイントワイズ畳み込みの計算総量:
Depthwise Separable Convolutionの計算総量:
この分析から、Depthwise Separable Convolutionは通常の畳み込みよりも計算効率がはるかに優れていることがわかります。特に、という典型的なカーネルサイズでは、計算量は約1/9に削減されます。
コード
# from https://github.com/sean-wade/MobileNetV1_2_3-Pytorch/blob/master/mobilenetv1.py
import torch
import torch.nn as nn
class MobileNetv1(nn.Module):
def __init__(self, n_class=1000):
# MobileNetV1のクラス定義。n_classは分類するクラス数(デフォルトは1000クラス)
super(MobileNet, self).__init__()
self.nclass = n_class
def conv_bn(inp, oup, stride):
# 標準的な畳み込み層 + Batch Normalization + ReLU
# inp: 入力チャネル数, oup: 出力チャネル数, stride: ストライド
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True)
)
def conv_dw(inp, oup, stride):
# Depthwise Separable Convolutionの実装 ★MobileNetの核心的革新部分★
return nn.Sequential(
# 深度方向畳み込み (Depthwise Convolution) - 各チャネルに独立した3x3カーネルを適用
# groups=inp により、各入力チャネルが独立して処理される
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
# ポイントワイズ畳み込み (Pointwise Convolution) - 1x1畳み込みでチャネル融合
# 入力チャネル数(inp)から出力チャネル数(oup)へ変換
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
# MobileNetV1のネットワーク構造定義
self.model = nn.Sequential(
# 最初の標準的な畳み込み層(3チャネルから32チャネルへ)
conv_bn(3, 32, 2),
# Depthwise Separable Convolutionブロック群
# ★MobileNetの主要な革新: 標準畳み込みの代わりにDSCを使用★
conv_dw(32, 64, 1), # 32->64チャネル, stride=1
conv_dw(64, 128, 2), # 64->128チャネル, stride=2 (ダウンサンプリング)
conv_dw(128, 128, 1), # 128->128チャネル, stride=1
conv_dw(128, 256, 2), # 128->256チャネル, stride=2 (ダウンサンプリング)
conv_dw(256, 256, 1), # 256->256チャネル, stride=1
conv_dw(256, 512, 2), # 256->512チャネル, stride=2 (ダウンサンプリング)
conv_dw(512, 512, 1), # 512->512チャネル, stride=1
conv_dw(512, 512, 1), # 512->512チャネル, stride=1
conv_dw(512, 512, 1), # 512->512チャネル, stride=1
conv_dw(512, 512, 1), # 512->512チャネル, stride=1
conv_dw(512, 512, 1), # 512->512チャネル, stride=1
conv_dw(512, 1024, 2), # 512->1024チャネル, stride=2 (ダウンサンプリング)
conv_dw(1024, 1024, 1), # 1024->1024チャネル, stride=1
# 最終的な平均プーリング
nn.AvgPool2d(7),
)
# 最終的な全結合層(分類層)
self.fc = nn.Linear(1024, self.nclass)
def forward(self, x):
# 順伝播の定義
x = self.model(x)
x = x.view(-1, 1024) # テンソルの形状変換
x = self.fc(x) # 最終的なクラス分類
return x
MobileNetV2: Inverted Residuals and Linear Bottlenecks
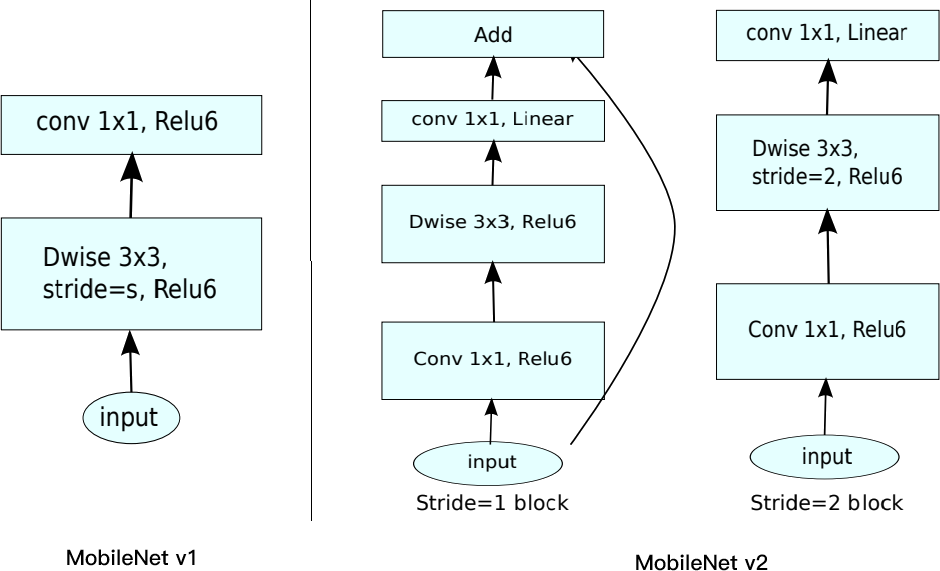
MobileNetV1と比較して、MobileNetV2は引き続きDepthwise Separable Convolutionを使用していますが、その主要構成モジュールは大きく変更されています。この新しい構造は「Bottleneck Residual Block」と呼ばれます。
Bottleneck Residual Blockの構造
このブロックは主に3つの畳み込み層で構成されています:
- 1×1 Expansion Layer(拡張層)
- 3×3 Depthwise Convolution(深度方向畳み込み)
- 1×1 Projection Layer(投影層)
Projection Layer(投影層)
MobileNetV1のPointwise Convolution(1×1畳み込み)は、チャネル数を維持するか2倍にするのに対し、MobileNetV2のProjection Layerはチャネル数を削減します。この層が「Projection(投影)」と呼ばれる所以は、高次元(多数のチャネル)のデータを低次元(少数のチャネル)のテンソルに投影するからです。例えば、144チャネルのテンソルを24チャネルに縮小します。この層は「Bottleneck Layer(ボトルネック層)」とも呼ばれ、ネットワーク内を流れるデータ量を減らします。
Expansion Layer(拡張層)
MobileNetV2に新しく追加された層で、これも1×1畳み込みです。この層の目的は、データがDepthwise Convolutionに入る前にチャネル数を拡張することです。Expansion Layerは、常にProjection Layerとは逆に、入力チャネル数よりも多くの出力チャネルを持ちます。拡張係数(Expansion Factor)は、チャネル数を何倍にするかを示すハイパーパラメータで、デフォルトは6です。
ブロックの処理フロー
例えば、24チャネルのテンソルがBottleneck Residual Blockに入力された場合:

- Expansion Layer: まず、24チャネルを 24 × 6 = 144チャネルに拡張します。
- Depthwise Convolution: 次に、この144チャネルのテンソルに3×3のフィルターを適用します。
- Projection Layer: 最後に、144チャネルを再び24チャネルなど、より少ないチャネル数に投影します。
| ステップ | 入力 (Input) | 演算子 (Operator) | 出力 (Output) | 説明 |
|---|---|---|---|---|
| 1 | h × w × k | 1×1 conv2d, ReLU6 | h × w × (tk) | Expansion Layer: チャネル数をt倍に拡張 • kチャネルからtkチャネルへ • 情報表現力の向上 |
| 2 | h × w × (tk) | 3×3 dwise, stride=s, ReLU6 | h/s × w/s × (tk) | Depthwise Convolution: 空間フィルタリング • 3×3カーネルで空間情報を処理 • ストライドsにより空間サイズを1/sに縮小 • チャネル数は維持(tk) |
| 3 | h/s × w/s × (tk) | linear 1×1 conv2d | h/s × w/s × k’ | Projection Layer: チャネル数をk’に圧縮 • 高次元特徴を低次元空間に投影 • 活性化関数なし(Linear) |
| 記号 | 意味 | 備考 |
|---|---|---|
| h, w | 入力特徴マップの高さと幅 | 空間次元 |
| k | 入力チャネル数 | ブロックへの入力チャネル数 |
| k’ | 出力チャネル数 | ブロックからの出力チャネル数 |
| t | 拡張係数 (Expansion Factor) | ハイパーパラメータ、デフォルト値は6 |
| s | ストライド (Stride) | 空間サイズを縮小するためのパラメータ |
このように、Bottleneck Residual Blockの入力と出力は低次元のテンソルであり、ブロック内で行われるフィルタリング処理は高次元のテンソルに対して行われます。
nverted Residual Connection(逆残差接続)
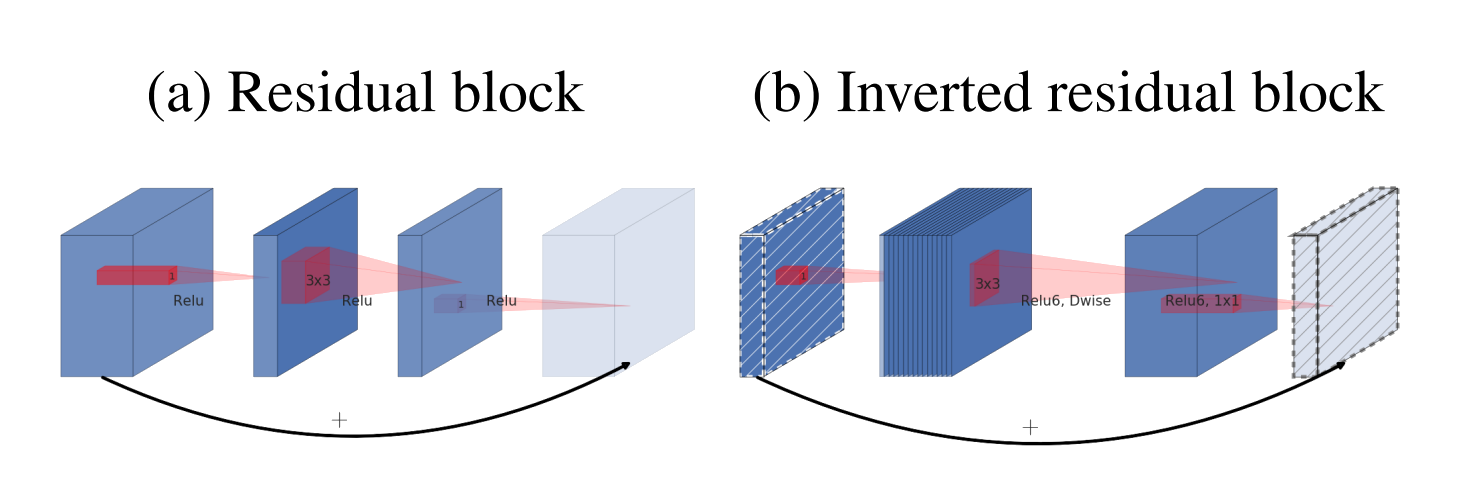
ResNetのResidual Connectionと同様に、勾配がネットワークを流れやすくするために存在します。入力チャネル数と出力チャネル数が同じ場合(例えば上の例の24チャネル)にのみ使用されますが、ブロックをいくつか通過するたびに出力チャネルが増加するため、常に使用されるわけではありません。
この構造により、計算リソースを効率的に活用しながらも、必要な情報を保持可能
MobileNetV2の改善意義
アーキテクチャの主な変更点
残差接続と拡張/投影層の導入
- MobileNetV2の核心的な変更は、残差接続と拡張層(Expansion Layer)・投影層(Projection Layer)の採用
- 従来のMobileNetV1の
Depthwise Separable Convolutionを維持しつつ、より効率的なブロック構造を構築
データフローの最適化
- ネットワークを通じてチャネル数が増加し、空間サイズが減少する進行パターン
- ブロック間の接続に
bottleneck layerを使用することで、テンソルを相対的に小さく保つ
計算効率と情報表現のバランス
低次元テンソルの利点と課題
- テンソルサイズを小さくすることで計算量を削減(テンソルが小さければ畳み込みの乗算も減少)
- しかし、単純に低次元テンソルを使用するだけでは十分な情報を抽出できない
Inverted Residualsの実質
- 従来(ResNet): 高次元→低次元→高次元(情報の圧縮と復元)
- MobileNetV2: 低次元→高次元→低次元(情報の一時的な拡張)
ネットワーク全体でテンソルサイズを小さく保ちつつ、必要な処理は高次元空間で実行。これにより、計算効率と情報表現のバランスを保ち、より高速かつ軽量なモデル構築が可能となる。
モデル比較表
| Network | Top-1 Accuracy (%) | Parameters | MAdds | CPU Time |
|---|---|---|---|---|
| MobileNetV1 | 70.6 | 4.2M | 575M | 113ms |
| ShuffleNet (1.5) | 71.5 | 3.4M | 292M | - |
| ShuffleNet (x2) | 73.7 | 5.4M | 524M | - |
| NasNet-A | 74.0 | 5.3M | 564M | 183ms |
| MobileNetV2 | 72.0 | 3.4M | 300M | 75ms |
| MobileNetV2 (1.4) | 74.7 | 6.9M | 585M | 143ms |
MobileNetV3
SE Blockの導入
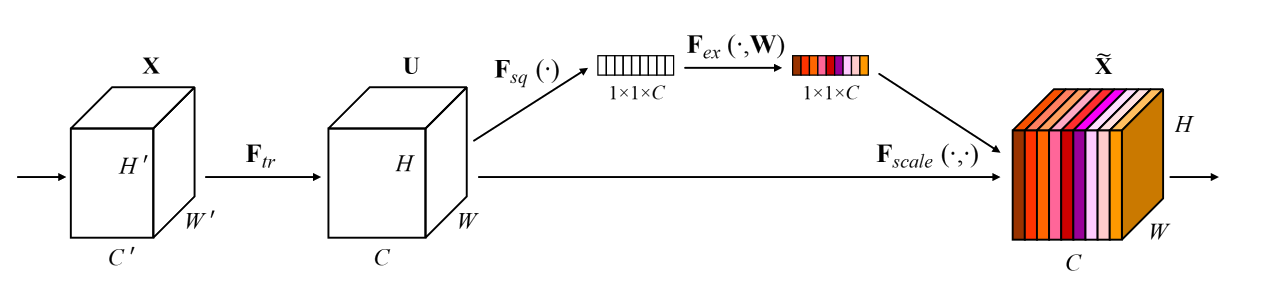
SE Moduleは、チャネル方向の注意力機構を導入することで、各チャネルの重要度に応じた重み付けを行うモジュールです。MobileNetV3など、多くの最新のCNNアーキテクチャで採用されています。
構造と処理フロー
-
Squeeze (圧縮):
- nn.AdaptiveAvgPool2d(1): 各チャネルの特徴マップ全体をグローバル平均プーリングし、空間次元を1×1に圧縮
- 結果: (B, C, H, W) → (B, C, 1, 1) (B:バッチサイズ, C:チャネル数)
-
Excitation (励起):
- 1×1 Conv + BN + ReLU: チャネル数を1/reductionに削減し、非線形変換
- 1×1 Conv + BN + hsigmoid: 元のチャネル数に戻し、0〜1の重みを生成
- 結果: 各チャネルに対する重要度スコア(重み)を計算
-
Scale (スケーリング):
- 元の入力 x と計算された重みを乗算
- 重要なチャネルは強調、重要でないチャネルは抑制
class SeModule(nn.Module):
def __init__(self, in_size, reduction=4):
super(SeModule, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1), # Global Average Pooling
nn.Conv2d(in_size, in_size // reduction, kernel_size=1, stride=1, padding=0, bias=False), # FC1
nn.BatchNorm2d(in_size // reduction),
nn.ReLU(inplace=True),
nn.Conv2d(in_size // reduction, in_size, kernel_size=1, stride=1, padding=0, bias=False), # FC2
nn.BatchNorm2d(in_size),
hsigmoid()) # Hard Sigmoid
def forward(self, x):
return x * self.se(x) # スケーリング
h-swish と h-sigmoid と Relu6(x + 3)/6
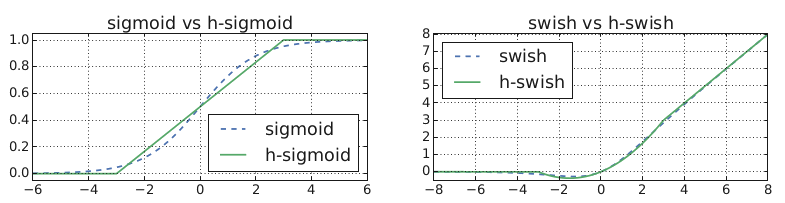
sigmoid関数の定義
Swishの数式
Swishの優位性
- 無上界・有下界: 出力範囲がではなく、下限があるため勾配消失問題に強い
- 平滑性: 微分可能で連続的な曲線を形成
- 非単調性: 単調増加ではなく、より複雑な非線形変換を可能にする
- 深層モデルでの優位性: ReLUよりも深いネットワークで優れた性能を発揮
計算効率の問題
- 標準的なsigmoid関数: は計算コストが高い
- モバイルデバイスなどリソース制限のある環境では実用性に課題
h-sigmoidを使用した表現
h-swishによる近似
特徴
- 非線形性: ReLUと同様に非線形変換を提供
- 滑らかさ: ReLUとは異なり、滑らかな曲線を形成(微分可能)
- 計算効率: 除算は定数による乗算として実装可能(例:)
- ハードウェアフレンドリー: ReLU6を使用することで、固定小数点演算での実装が容易
近似の利点
-
ハードウェアフレンドリー:
- ほぼすべてのソフトウェア・ハードウェアフレームワークでReLU6の最適化実装が利用可能
- 異なるsigmoid実装による数値精度の問題を回避
-
計算効率:
- 除算は定数乗算()として実装可能
- ReLU6は区分線形関数で実装が容易
MobileNetV3での応用戦略
適用箇所の選択
- 第1層と後半層のみに適用: ネットワークの深い層で非線性活性化関数の効果が顕著なため
- パラメータ削減: 深層でのみ使用することで計算コストを抑えながら性能向上を実現
設計思想
- ネットワークが深くなるにつれて、非線形活性化関数の導入コストが低下することを利用
- Swishの大部分の利点は深層での使用によって得られることに基づく戦略
このように、MobileNetV3では計算効率と精度のバランスを取るために、h-swishというハードウェアフレンドリーな近似関数を戦略的に使用する設計が採用されています。
class hswish(nn.Module):
def forward(self, x):
out = x * F.relu6(x + 3, inplace=True) / 6
return out
class hsigmoid(nn.Module):
def forward(self, x):
out = F.relu6(x + 3, inplace=True) / 6
return out
出力層の変更
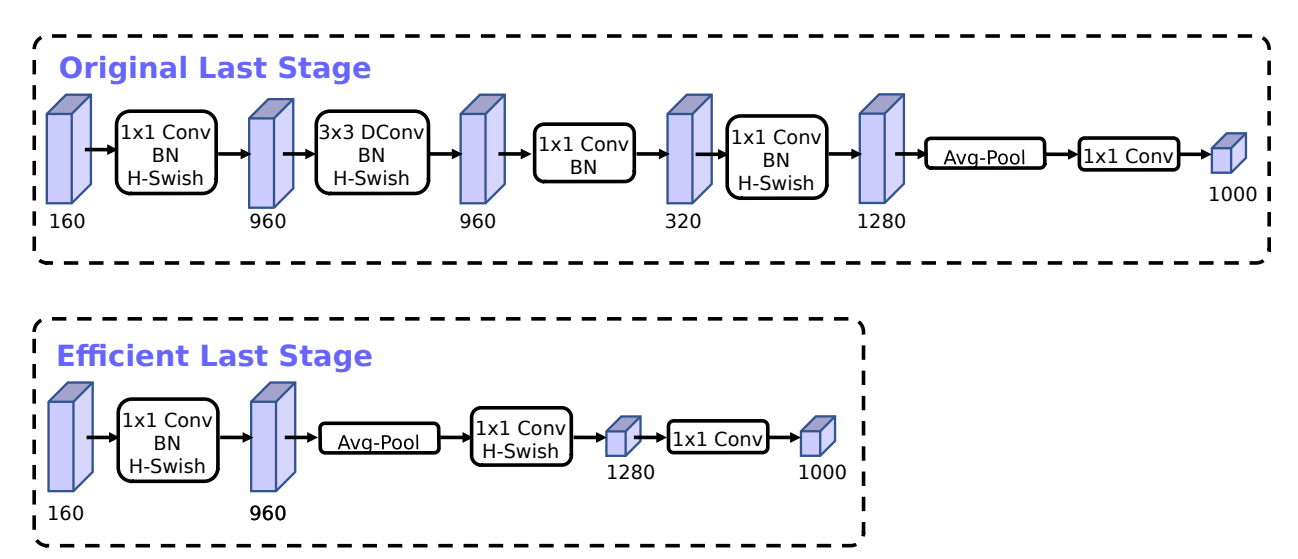
- ボトルネック層接続の削除: 従来の残差接続を出力層から削除
- パラメータ削減: ネットワークパラメータを効果的に11%削減
- 推論時間の短縮: 推論時間を11%削減しながらも、性能はほぼ維持
out = F.avg_pool2d(out, 7)
out = out.view(out.size(0), -1)
out = self.hs3(self.bn3(self.linear3(out)))
out = self.linear4(out)
return out
参考
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNetV2: Inverted Residuals and Linear Bottlenecks
Searching for MobileNetV3