
ConvNeXt解読
ConvNeXt
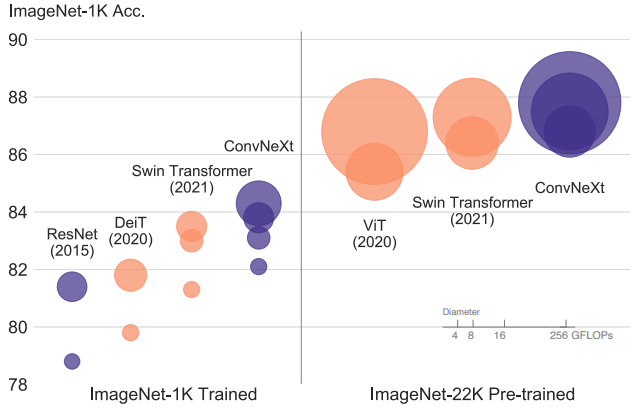
ConvNeXtは、特に新しい構造やイノベーションがあるわけではなく、既存のネットワークで使われている細かい設計要素を適切に組み合わせることで、ImageNetのTop-1精度を向上させました。この設計の動機は非常にシンプルで、「TransformerやSwin-Transformerがどのようにしているかを参考にして、効果があれば採用する」という方針に従っています。
ConvNeXtの進化経路
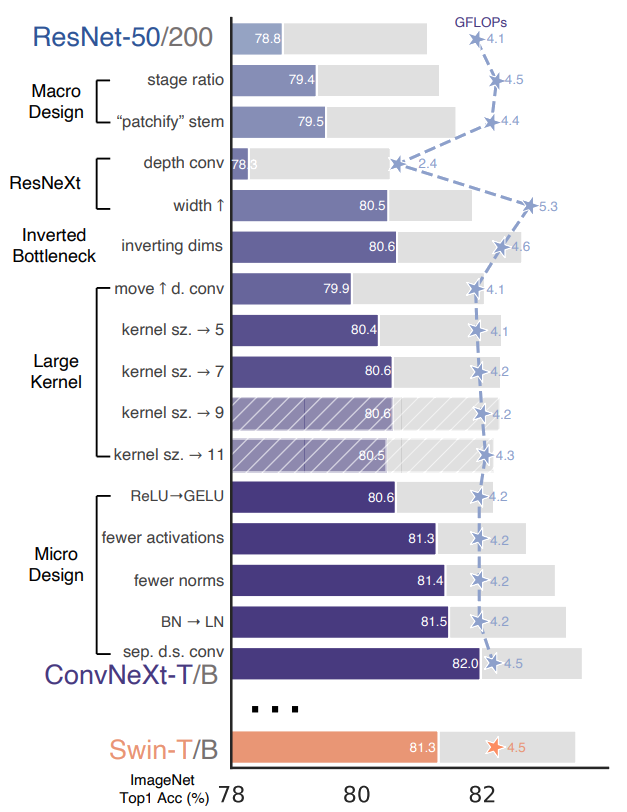
ConvNeXtはResNet-50やResNet-200を出発点として、以下の5つの観点から順次改善を行いました:
- マクロ設計
- 深度方向分離畳み込み(ResNeXt)
- 逆ボトルネック層(MobileNet v2)
- 大きな畳み込みカーネル
- 他のの改善点
マクロ設計
Swin Transformerのマクロネットワーク設計を分析し、それに基づいてConvNeXtの設計を改善します。Swin Transformerは従来のConvNetsと同様にマルチステージ設計を採用しており、各ステージで異なる特徴マップ解像度を持っています。
ステージ計算比率の変更
ResNetにおけるオリジナルの計算分布設計は主に経験則に基づいていました。「res4」ステージが重めに設計されているのは、物体検出などの下流タスクとの互換性を考慮した結果で、検出器ヘッドが14×14の特徴平面で動作するためです。
一方、Swin-Tは同じ原則に従いながらも、わずかに異なるステージ計算比率(1:1:3:1)を採用しています。より大きなSwin Transformerでは、この比率は1:1:9:1になります。
この設計に従い、ResNet-50の各ステージのブロック数を(3, 4, 6, 3)から(3, 3, 9, 3)に調整しました。これにより、Swin-Tと同程度のFLOPsとなり、モデル精度が78.8%から79.4%に向上しました。計算の分布については多くの研究が行われており、より最適な設計が存在する可能性があります。
今後はこのステージ計算比率を使用します。
Stemを「Patchify」に変更
通常、stem cell設計は入力画像がネットワークの最初でどのように処理されるかに関係しています。自然画像に内在する冗長性のため、標準的なConvNetsとVision Transformersの両方で、一般的なstem cellは入力画像を適切な特徴マップサイズに積極的にダウンサンプリングします。
標準的なResNetのstem cellは、ストライド2の7×7畳み込み層と最大プール層を含み、これにより入力画像が4倍ダウンサンプリングされます。Vision Transformersでは、より積極的な「patchify」戦略がstem cellとして使用され、これは大きなカーネルサイズ(例:カーネルサイズ=14または16)と非オーバーラップ畳み込みに対応します。
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
Swin Transformerは同様の「patchify」層を使用しますが、アーキテクチャのマルチステージ設計に対応するため、パッチサイズは4と小さくなっています。ResNetスタイルのstem cellを、4×4、ストライド4の畳み込み層で実装されたpatchify層に置き換えました。これにより、精度は79.4%から79.5%に変化しました。これは、ResNetのstem cellがViT風のよりシンプルな「patchify」層に置き換えられても、同様の性能が得られることを示唆しています。
ネットワークでは「patchify stem」(4×4非オーバーラップ畳み込み)を使用します。
逆ボトルネック層と深度方向分離畳み込み
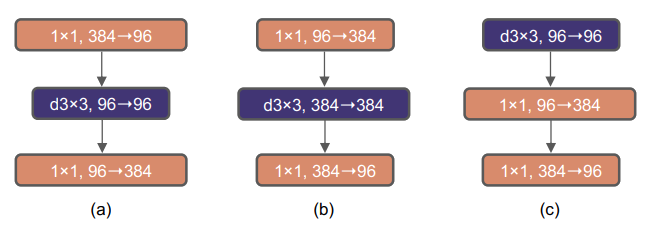
この図は、異なるブロック構造の変更とその仕様を示しています。
a. ResNeXtブロック
- 従来のResNeXtアーキテクチャのブロック構造
- グループ化された畳み込みを使用して計算効率を向上
- 通常のボトルネック構造に基づく設計
b. 逆ボトルネックブロック
- 逆ボトルネック(Inverted Bottleneck)構造を採用
- Transformerブロックと同様の設計思想
- MLPブロックの隠れ次元が入力次元の4倍の幅を持つ
- この構造によりネットワーク全体のFLOPsが4.6Gに削減
- パフォーマンスが80.5%から80.6%にわずかに改善
c. 空間的深度方向畳み込み層の位置変更
- 空間的な深度方向畳み込み層(spatial depthwise conv layer)の位置を上方に移動
- ブロック内の処理順序を変更した変種構造
効果:
- GFLOPs: 4.4 → 2.4(削減)
- 精度: 79.5% → 78.3%(低下)
精度低下の補償:
- ResNet-50の基本チャネル数を64から96に増加
結果:
- GFLOPs: 5.3に増加
- 精度: 80.5%に向上
大きな畳み込みカーネル
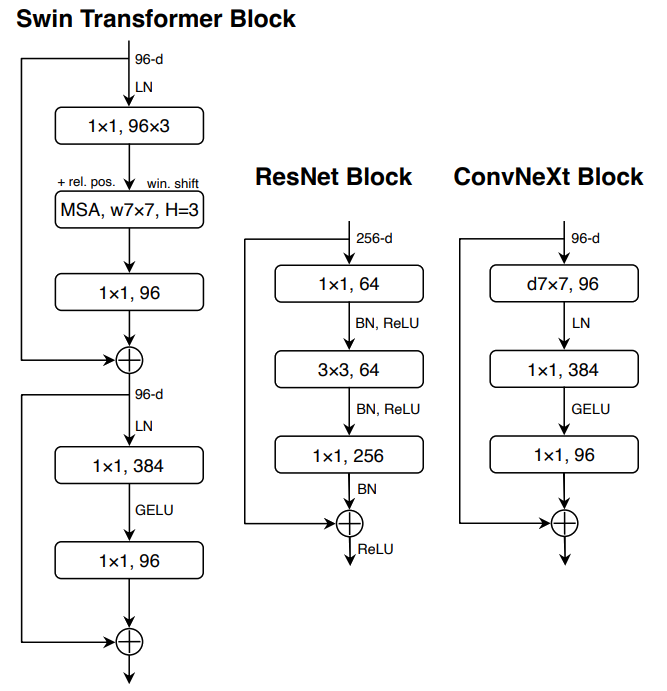
この図は、ResNet、Swin Transformer、およびConvNeXtのブロック設計を比較しています。
- ResNetブロック
- 従来のResNetアーキテクチャのブロック構造
- 3×3の標準畳み込み層を使用
- 単純な構造で、主にボトルネック構造に基づく設計
- Swin Transformerブロック
- Swin Transformerのブロック構造はより洗練されている
- 複数の専用モジュールが存在
- 2つの残差接続(residual connections)を持つ
- マスクされた自己注意(MSA)ブロックとMLPブロックを含む
- ConvNeXtブロック
- 提案されたConvNeXtのブロック設計
- Swin Transformerの設計思想を取り入れながら簡素化
- Transformer MLPブロック内の線形層も「1×1畳み込み」として表現(等価であるため)
深度方向畳み込み層の位置変更
- Transformerの設計と一致させるため、深度方向畳み込み層の位置を上方に移動
- 逆ボトルネック構造を持つ場合、これは自然な設計選択となる
- 複雑/非効率なモジュール(大規模カーネル畳み込み)はチャネル数を減らし、効率的な1×1層が主要な処理を行う
カーネルサイズの拡大
様々なカーネルサイズ(3, 5, 7, 9, 11)で実験を実施:
| カーネルサイズ | 性能 | FLOPs |
|---|---|---|
| 3×3 | 79.9% | 4.1G |
| 7×7 | 80.6% | 同程度 |
- 7×7のカーネルサイズで性能が顕著に向上
- 7×7を超えると性能向上が頭打ちになることが確認されている
- 大容量モデル(ResNet-200)でも同様の傾向を確認
他の変更点
活性化関数の変更
ReLUからGELUへの置換
- NLPとVisionアーキテクチャの違いの一つは活性化関数の選択
- 従来はReLUがConvNetで広く使用されていたが、GELUは最先端のTransformerで使用
- ConvNetでもReLUをGELUに置換可能(精度: 80.6%→80.6%、変化なし)
活性化関数の削減
- Transformerブロックは活性化関数が少ない
- 通常、MLPブロック内に1つの活性化関数のみ
- ResNetでは各畳み込み層に活性化関数を追加するのが一般的
- 残差ブロックからGELU層を削除し、2つの1×1層の間に1つだけ配置
- 結果: 精度が0.7%向上し81.3%に(Swin-Tと同等の性能)
正規化層の改善
正規化層の削減
- Transformerブロックは正規化層も少ない
- 2つのBatchNorm(BN)層を削除し、1×1畳み込み層の前に1つのBN層のみを保持
- 結果: 精度がさらに向上し81.4%に(Swin-Tを上回る)
BNからLNへの置換
- BatchNormはConvNetの重要なコンポーネントだが、複雑な側面もある
- TransformerではLayer Normalization(LN)が使用され良好な性能を発揮
- 修正されたアーキテクチャと学習技術により、LNを使用しても問題なく学習可能
- 結果: 精度が81.5%に向上
ダウンサンプリング層の分離
ダウンサンプリングの変更
- ResNet: 各ステージの最初の残差ブロックで空間ダウンサンプリング(3×3 conv、ストライド2)
- Swin Transformer: ステージ間に独立したダウンサンプリング層を追加
- ConvNeXt: 2×2 conv層、ストライド2を使用して空間ダウンサンプリング
学習安定化のための正規化層追加
- 空間解像度が変更される場所に正規化層を追加
- ダウンサンプリング層の前、stemの後、最終グローバル平均プーリング後のLN層を追加
- 結果: 精度が82.0%に向上(Swin-Tの81.3%を大幅に上回る)
コード分析
ConvNeXt Block コード
class Block(nn.Module):
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
# 深度方向分離畳み込み (depthwise conv) - 大きなカーネルサイズ(7x7)を使用
# groups=dim により、各チャネルに独立した畳み込みを適用
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)
# LayerNormを使用 - BatchNormから変更された重要な改善点
# 画像データを(N, C, H, W)から(N, H, W, C)に変換してから適用
self.norm = LayerNorm(dim, eps=1e-6)
# 1x1畳み込みを線形層で実装 - TransformerのMLPブロックと同等
# 逆ボトルネック構造: 入力チャネル数の4倍に拡張
self.pwconv1 = nn.Linear(dim, 4 * dim)
# GELU活性化関数 - ReLUから変更された活性化関数
self.act = nn.GELU()
# 1x1畳み込みを線形層で実装 - 逆ボトルネック構造の出力層
# 4倍に拡張されたチャネル数を元のチャネル数に戻す
self.pwconv2 = nn.Linear(4 * dim, dim)
# Layer Scale - 学習可能なスケーリング係数
# 初期値が非常に小さい(1e-6)ことで学習の安定化を図る
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True) if layer_scale_init_value > 0 else None
# DropPath - ランダム深度の実装
# 学習時の正則化として機能し、過学習を防止
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x # 残差接続用に入力値を保存
# 深度方向畳み込みの適用
x = self.dwconv(x)
# LayerNormのために次元の順序を変更 (N, C, H, W) -> (N, H, W, C)
x = x.permute(0, 2, 3, 1)
# LayerNormの適用
x = self.norm(x)
# 1x1畳み込み(線形層)と活性化関数の適用 - MLPブロックと同等
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
# Layer Scaleの適用 (学習可能なスケーリング)
if self.gamma is not None:
x = self.gamma * x
# 次元の順序を元に戻す (N, H, W, C) -> (N, C, H, W)
x = x.permute(0, 3, 1, 2)
# 残差接続とDropPathの適用
x = input + self.drop_path(x)
return x
ダウンサンプリング層の分離コード
self.downsample_layers = nn.ModuleList()
# stem層もダウンサンプリング層として扱い、downsample_layersに統合
# 推論時にはインデックスでアクセスするため、すべてのダウンサンプリング処理を一元管理
stem = nn.Sequential(
# パッチ化された埋め込み: 4x4のカーネル、ストライド4で入力画像をダウンサンプリング
# 224x224の入力が56x56の特徴マップに変換される
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
# LayerNormを適用 - BatchNormからLayerNormへの重要な変更点
# data_format="channels_first"により、(N, C, H, W)形式に対応
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
# 3つのステージ間のダウンサンプリング層を定義 (合計4ステージなので3回のダウンサンプリングが必要)
for i in range(3):
downsample_layer = nn.Sequential(
# ダウンサンプリング前のLayerNorm - 学習安定化のための重要な改善点
# Swin Transformerの設計思想を取り入れ、独立した正規化層を追加
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
# 2x2のカーネル、ストライド2で空間解像度を半分にダウンサンプリング
# ResNetの3x3 conv, stride=2から変更された重要なポイント
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)