
VITS論文の解読
目次
VITS
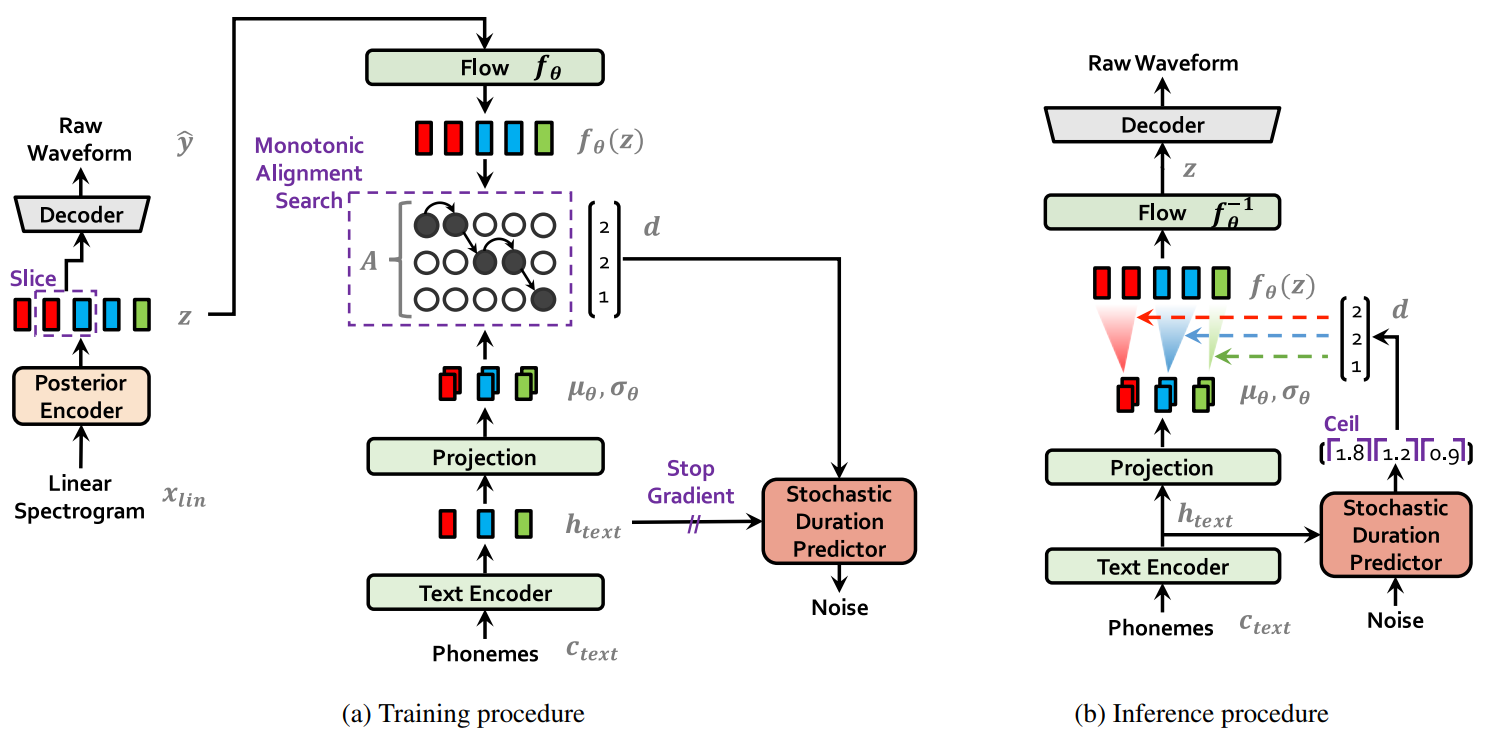
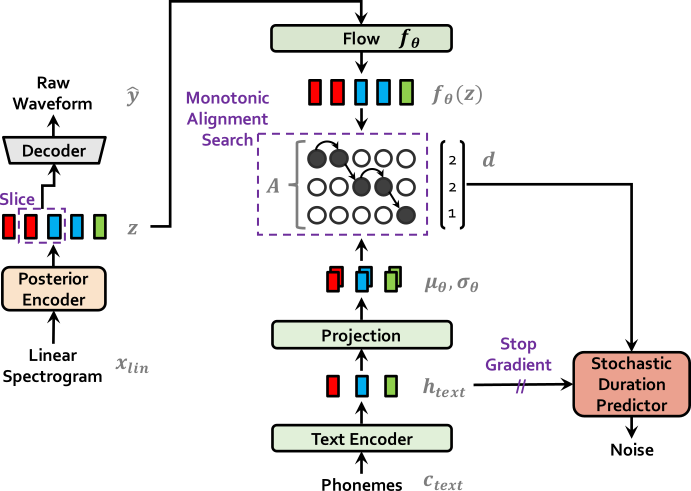
VITS(Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech(ICML 2021))は、変分推論(variational inference)、正規化フロー(normalizing flows)、および敵対的学習を組み合わせた、表現力の高い音声合成モデルです。VITSは、音声合成における音響モデルとボコーダーをスペクトログラムではなく潜在変数で連結し、潜在変数上で確率モデリングを行い、確率的デュレーション予測器を利用することで、合成音声の多様性を向上させています。同じテキストを入力しても、異なるトーンやリズムの音声を合成することが可能になります。
論点アドレス:https://proceedings.mlr.press/v139/kim21f/kim21f.pdf
コードアドレス:https://github.com/jaywalnut310/vits
demoアドレス:https://jaywalnut310.github.io/vits
主な貢献点
-
並列エンドツーエンドTTS手法の提案
- 従来の2段階モデルよりも自然な音声を生成可能
- 全体が一つのネットワークで構成され、効率的な学習と推論が実現
-
変分推論の強化
- 正規化フローと敵対的訓練プロセスにより、生成モデルの表現能力を向上
- より高品質な音声合成が可能に
-
確率的持続時間予測器の導入
- 入力テキストから異なるリズムを持つ音声を合成可能
- 自然なone-to-many関係を表現(同じテキストを異なるトーンとリズムで複数の方法で発話可能)
モデルアーキテクチャ
-
音声情報入力: メルスペクトログラム: 音声データの短時フーリエ変換から得られる:
Posterior Encoder(WaveNetモデル) で潜在変数zの事後分布を取得 -
Decoder: HiFiGANのジェネレーターと同等: 生の音声データを直接生成し、中間特徴量(メルスペクトログラム)の生成やボコーダーの訓練を不要に
-
Flow: 事後分布qから事前分布pへの変換関数fとして機能: 信号の表現能力を強化
-
Monotonic Alignment Search: 音声とテキストのベクトル系列の長さを一致させる
-
Text Encoder: 多頭注意transformer構造を使用: 入力テキストを音素系列に変換し、さらにベクトル系列に変換
-
Projection: ベクトル系列に基づいての事前分布パラメータ(, )を取得
-
Stochastic Duration Predictor: Flowモデルを使用して周期予測を行う
-
Discriminator: 生成されたRaw Waveformと実際の音声波形を識別する一組の識別器
トレーニング
変分推論(Variational Inference)
VITSの生成器は、変分下界(ELBO: Evidence Lower Bound)を最大化する条件付きVAEとして考えることができます。これは以下の目的関数を最適化することを意味します:
重建損失(Reconstruction Loss)
訓練時には、モデルの学習を導くためにメルスペクトログラムを生成します。重建損失の目標サンプルには、生の波形ではなくメルスペクトログラムが使用されます:
推論時にはメルスペクトログラムの生成は不要で、この損失は訓練中のみ計算に使用されます。
KLダイバージェンス(KL Divergence)
事前エンコーダーの入力には、テキストから生成された音素と音素・潜在変数間のアライメントが含まれます。アライメントとは、サイズの厳密単調注意行列で、各音素の発音時間を表します。KLダイバージェンスは以下の通りです:
ここで:
- は線形スペクトログラムが与えられたときの潜在変数の事後分布
- は条件が与えられたときの潜在変数の事前分布
- 潜在変数は以下に従います:
より高解像度の情報を事後エンコーダーに提供するために、メルスペクトログラムではなく線形スペクトログラムを入力として使用します。よりリアルなサンプルを生成するために、事前分布の表現能力を向上させることが重要であるため、正規化フローを導入して、テキストエンコーダーが生成する単純な分布と潜在変数に対応する複雑な分布の間で可逆変換を行います:
ここで入力はアップサンプリングされたエンコーダー出力です:
アライメント推定(Alignment Estimation)
訓練時には「アライメント」の真のラベルがないため、訓練フェーズの各イテレーションでテキストと音声の間のアライメントを推定する必要があります。
単調アライメント探索(Monotonic Alignment Search: MAS)
テキストと音声の間のアライメントを推定するために、VITSはGlow-TTSと同様の単調アライメント探索(MAS)手法を採用しています。この手法は、正規化フローでパラメータ化されたデータの対数尤度を最大化する最適なアライメントパスを探すことを試みます:
MASによって得られる最適アライメントは単調かつスキップなしである必要がありますが、VITSの最適化目標は決定論的な潜在変数の対数尤度ではなくELBOであるため、MASを直接VITSに適用することはできません。そのため、ELBOを最大化する最適なアライメントパスを探すためにMASを若干変更しています:
テキストからの持続時間予測
確率的持続時間予測器はフローに基づく生成モデルであり、持続時間シーケンスと同じ時間解像度と次元を持つ確率変数とを導入します。近似事後分布を使用してこれらの変数をサンプリングし、訓練目標は音素持続時間の対数尤度の変分下界です:
訓練の時には、他のモジュールに影響を与えるのを防ぐために、確率的持続時間予測器からの勾配伝播を遮断します。音素の持続時間は、確率的持続時間予測器の可逆変換を通じてランダムノイズからサンプリングされ、その後整数値に変換されます。
敵対的学習(Adversarial Training)
判別器を導入して、出力がデコーダーからの出力か、実際の波形かを判断します。VITSは2種類の損失関数を使用します:
-
敵対的学習用の最小二乗損失関数:
-
生成器に特別に適用される特徴マッチング損失(feature-matching loss):
ここでは判別器の層数、は第層の判別器出力特徴マップ、は特徴マップの数です。特徴マッチング損失は、判別器の中間層出力を制約する再構成損失と見なすことができます。
理解
この訓練プロセスにより、VITSは以下のような特徴を持つことができます:
- 高品質な音声合成: VAEとGANの結合により、自然でリアルな音声生成が可能
- 多様性の向上: 潜在変数と確率的持続時間予測により、同じテキストから異なるトーンやリズムの音声を生成可能
- エンドツーエンド学習: 伝統的な2段階モデルよりも効率的な学習と推論が実現
- 自己教師あり学習: アライメントラベルなしでの学習が可能