
ResNetの説明
目次
ResNetは2015年に何凱明氏ら(マイクロソフト研究機関)より開発された畳み込みネットワーク(CNN)をベースにした深層学習モデルであり、深層ニューラルネットワークにおける重要なブレークスルーを提供する。
CNN従来ネットワークの課題
ResNetが提案される前は、すべてのニューラルネットワークは畳み込み層とプーリング層の積み重ねで構成されていた。
研究者たちは、畳み込み層とプーリング層をより多く重ねることで、画像の特徴情報をより完全に取得でき、学習効果も良くなると考えていた。しかし、実際の実験では、畳み込み層とプーリング層を重ねていくにつれて、学習効果が良くなるどころか…
問題1:勾配消失と勾配爆発
勾配消失:各層の誤差勾配が1未満の場合、逆伝播時にネットワークが深くなるほど勾配は0に近づく
勾配爆発:各層の誤差勾配が1より大きい場合、逆伝播時にネットワークが深くなるほど勾配は大きくなる
問題2:劣化問題(Degradation Problem)
CNNは、層数が増加するにつれて、予測性能が悪化する。
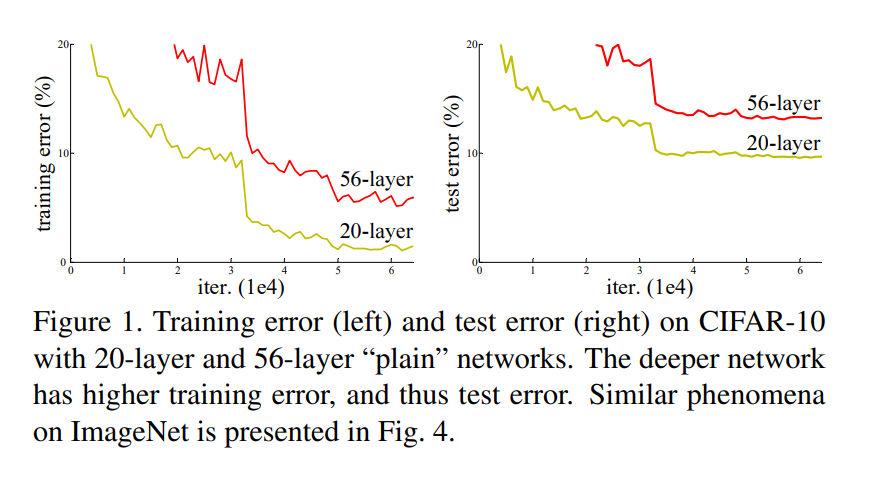
図から、20層の時の誤差率が最も低く、56層に増加されても悪化する。
ResNetの解決策
- ショートカット接続:層を飛び越えて接続することで勾配の逆伝播を容易にする
- 残差構造:入力を直接出力に加算することで学習を容易にする
- Batch Normalization:データの前処理とネットワーク内の正規化により学習安定化
Residual Block
残差学習は、ResNetが解決しようとするネットワークの劣化問題に対する核心的なアプローチです。
劣化問題の直感的理解
- 浅層ネットワークがあるとき、新たな層を追加して深層ネットワークを構築することを考える
- 最悪の場合、追加された層は何も学習せず、浅層ネットワークの特徴をそのまま複製する(恒等写像)
- この場合でも、深層ネットワークは少なくとも浅層ネットワークと同じ性能を持つはず
- しかし実際には性能が劣化するため、従来の学習方法に問題があると判断
残差学習のアイディア
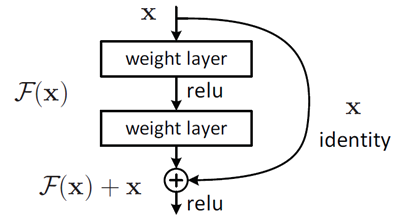
従来の学習目標の変更:
ここで:
-
: l番目の残差ユニットの入力
-
: l番目の残差ユニットの出力
-
: 残差関数(学習対象)
-
: 恒等写像(ショートカット接続)
-
: ReLU活性化関数
-
元の目標: 入力
xから特徴H(x)を直接学習 -
新しい目標: 残差
F(x) = H(x) - xを学習し、最終出力をF(x) + xとする
順伝播の特徴
浅層 から深層 までの特徴は以下のように表されます:
これは、出力が入力と各層の残差関数の和であることを示しており、ショートカット接続により情報が直接伝播されることを意味します。
勾配伝播の改善
この式:
- 第1項 : 損失関数からL層までの勾配
- 第2項の1: ショートカット接続(恒等写像)による勾配の無損失伝播を示す。この1があることで、勾配が直接入力層まで流れることができます。
- 第3項 : 重みを介した残差勾配で、通常のネットワークパスを通る勾配を表す。
ResNet
ResNetには2種類の残差ユニットが存在し、ネットワークの深さに応じて使い分けられています:
ネットワークの特徴
- 極めて深いネットワーク構造(1000層以上)
- residual(残差)モジュールの提案
- Batch Normalizationを用いた学習の高速化(dropoutを廃止)
2種類の残差ユニット
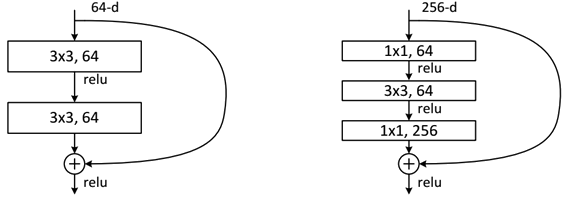
- 基本的な残差ユニット(basicblock)(浅層ネットワーク用)
- 18層や34層のResNetで使用
- 比較的シンプルな構造
- ボトルネック残差ユニット(bottleneck)(深層ネットワーク用)
- 50層、101層、152層のResNetで使用
- 計算効率を考慮した複雑な構造
- ショートカット接続の処理方法
- ショートカット接続はResNetの核心的な要素ですが、入出力の次元が異なる場合に特別な処理が必要です
コード例
BasicBlock
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
"""BasicBlock"""
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(BasicBlock, self).__init__()
# BNレイヤーでバイアスを使う必要はない
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=3, padding=1, stride=stride, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel) # BN層、BN層はコンボ層とリル層の中間に使用される。
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
self.relu = nn.ReLU(inplace=True)
# 順伝播
def forward(self, X):
identity = X
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.downsample is not None: # 元の入力Xのサイズは、積み重ねたときにメインブランチの畳み込み後の出力のサイズと同じ次元であることが保証される
identity = self.downsample(X)
return self.relu(Y + identity)
Bottleneck
class BottleNeck(nn.Module):
"""BottleNeck"""
# BottleNeckモジュールの最終的な出力out_channelは、Residualモジュールの入力in_channelの4倍のサイズ(Residualモジュールの入力は64)であり、ショートカットブランチのin_channelはResidualの入力64である。
# はResidualの入力64なので、元の入力画像Xと同じサイズにするために、Residualのin_channelをショートカットブランチで4倍に拡張する必要がある。
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(BottleNeck, self).__init__()
# デフォルトの生入力は256で、7x7レイヤーと3x3レイヤーの後、BottleNeckの入力は64に減少する。
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel) # BN层, BN层放在conv层和relu层中间使用
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.conv3 = nn.Conv2d(out_channel, out_channel * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channel * self.expansion) # レイヤー3のout_channelはin_channelの4倍に拡張される。
self.downsample = downsample
self.relu = nn.ReLU(inplace=True)
# 順伝播
def forward(self, X):
identity = X
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.relu(self.bn2(self.conv2(Y)))
Y = self.bn3(self.conv3(Y))
if self.downsample is not None: # 元の入力Xのサイズは、積み重ねたときにメインブランチの畳み込み後の出力のサイズと同じ次元であることが保証される
identity = self.downsample(X)
return self.relu(Y + identity)
ResNet-18
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as modelzoo
# from modules.bn import InPlaceABNSync as BatchNorm2d
resnet18_url = 'https://download.pytorch.org/models/resnet18-5c106cde.pth'
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
def __init__(self, in_chan, out_chan, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(in_chan, out_chan, stride)
self.bn1 = nn.BatchNorm2d(out_chan)
self.conv2 = conv3x3(out_chan, out_chan)
self.bn2 = nn.BatchNorm2d(out_chan)
self.relu = nn.ReLU(inplace=True)
self.downsample = None
if in_chan != out_chan or stride != 1:
self.downsample = nn.Sequential(
nn.Conv2d(in_chan, out_chan,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_chan),
)
def forward(self, x):
residual = self.conv1(x)
residual = F.relu(self.bn1(residual))
residual = self.conv2(residual)
residual = self.bn2(residual)
shortcut = x
if self.downsample is not None:
shortcut = self.downsample(x)
out = shortcut + residual
out = self.relu(out)
return out
def create_layer_basic(in_chan, out_chan, bnum, stride=1):
layers = [BasicBlock(in_chan, out_chan, stride=stride)]
for i in range(bnum-1):
layers.append(BasicBlock(out_chan, out_chan, stride=1))
return nn.Sequential(*layers)
class Resnet18(nn.Module):
def __init__(self):
super(Resnet18, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = create_layer_basic(64, 64, bnum=2, stride=1)
self.layer2 = create_layer_basic(64, 128, bnum=2, stride=2)
self.layer3 = create_layer_basic(128, 256, bnum=2, stride=2)
self.layer4 = create_layer_basic(256, 512, bnum=2, stride=2)
self.init_weight()
def forward(self, x):
x = self.conv1(x)
x = F.relu(self.bn1(x))
x = self.maxpool(x)
x = self.layer1(x)
feat8 = self.layer2(x) # 1/8
feat16 = self.layer3(feat8) # 1/16
feat32 = self.layer4(feat16) # 1/32
return feat8, feat16, feat32
def init_weight(self):
state_dict = modelzoo.load_url(resnet18_url)
# state_dict = torch.load('/apdcephfs/share_1290939/kevinyxpang/STIT/resnet18-5c106cde.pth')
self_state_dict = self.state_dict()
for k, v in state_dict.items():
if 'fc' in k: continue
self_state_dict.update({k: v})
self.load_state_dict(self_state_dict)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, nn.BatchNorm2d):
nowd_params += list(module.parameters())
return wd_params, nowd_params