
生成敵対ネットワーク (GAN) 理論と実装 (PyTorch)
2024/4/3
AI
目次
GAN紹介
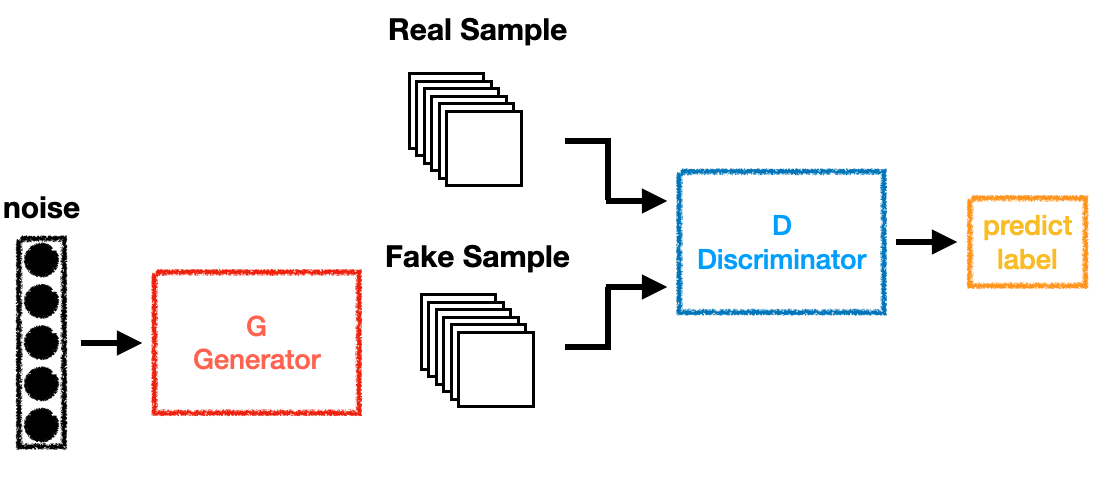
GAN(生成敵対ネットワーク)は、2014年にIan Goodfellowによって提案された深層生成モデルの一種です。このモデルは、生成器 (Generator) と判別器 (Discriminator) の2つのニューロンネットワークから構成され、互いに競争しながら学習を進めます。
基本的な構造
-
生成器 (Generator):
- 入力としてランダムノイズ $ z $ を受け取ります。
- 出力として疑似データ $ G(z) $ を生成します。
- 目標:本物のデータ分布に近づけ、判別器をだます。
-
判別器 (Discriminator):
- 入力として本物のデータ $ x $ または生成器からの出力 $ G(z) $ を受け取ります。
- 出力として、入力が本物である確率 $ D(x) $ を返します。
- 目標:正しく本物と偽物を識別すること。
GANのワークフロー
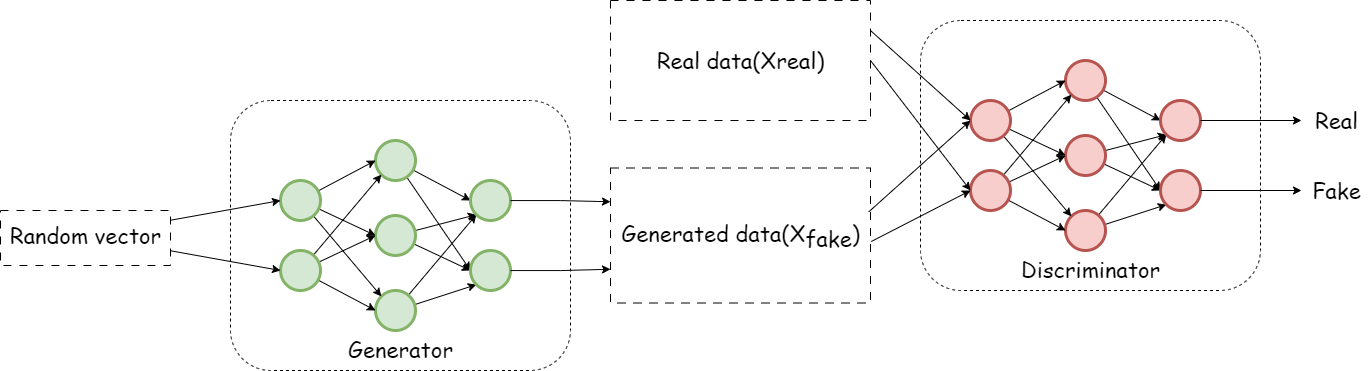
- 対抗プロセス: 生成器はできるだけリアルなデータを作り出し、判別器はそれに気づけるように精度を高めようとします。
- 学習過程では、両者が互いに改善し合い、最終的に生成器は非常に質の高いデータを生成できるようになります。
目的関数
GANの目的関数はミニマックスゲームとして定義されます:
- 判別器 $ D $ はこの式を最大化しようと努力し、本物と偽物を見分ける能力を高めます。
- 一方で生成器 $ G $ はこの式を最小化しようと努め、判別器をだませるようなリアルなデータを生成します。
初期準備
- ランダムノイズ $ z $ を用意:通常、正規分布や一様分布からサンプリングされた潜在変数。
- 本物データ $ x $ :訓練用データセットから抽出される真のデータ(例:画像など)。
- 生成器 $ G(z) $ と 判別器 $ D(x) $ のニューラルネットワーク構造を定義し、初期化します。
生成器の学習ステップ
-
新しいノイズ $ z $ を生成
- 判別器に対して新たな偽データ $ G(z) $ を送ります。
-
判別器による評価を受け取る
- $ D(G(z)) $:このときの判別器の出力を取得。
-
損失関数の計算
- 生成器の損失関数(判別器をだませたかどうか):
-
勾配降下法で生成器のみ更新
- 生成器のパラメータを更新して、よりリアルなデータを生成できるようにします。
判別器の学習ステップ
-
データ準備
- 真のデータ $ x \sim p_{data}(x) $ と、生成器によって作られた偽のデータ $ G(z) $ を使用します。
-
判別器の予測
- $ D(x) $:本物データに対する出力(1に近いほど「本物」と判断)
- $ D(G(z)) $:生成器からの出力に対する出力(0に近いほど「偽物」と判断)
-
損失関数の計算
- 判別器の損失関数:
-
勾配降下法で判別器のみ更新
- 判別器のパラメータを更新して、より正確に本物・偽物を識別できるようにします。
反復学習
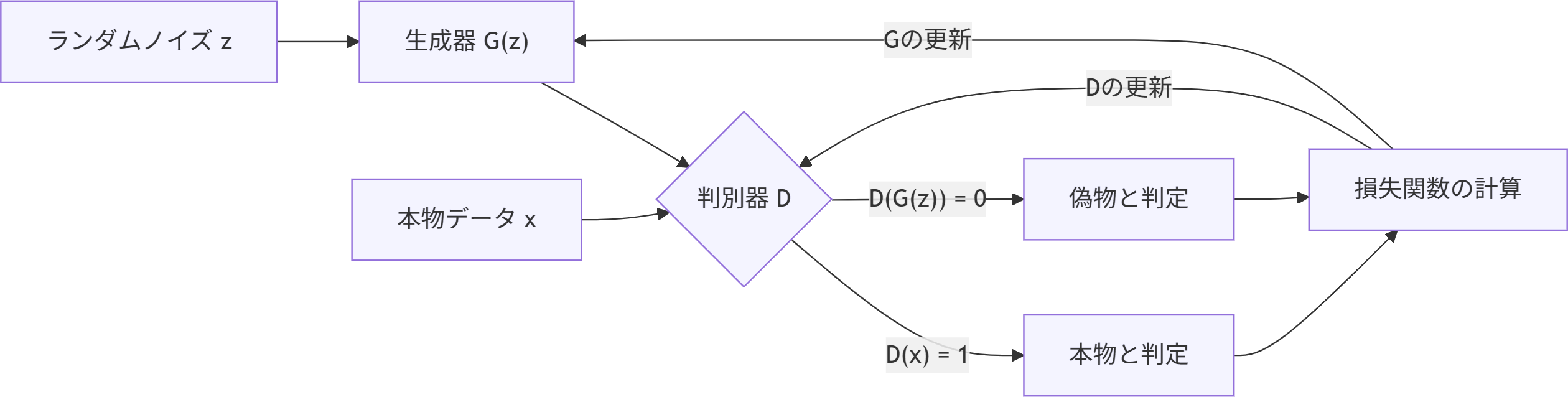
- 上記の生成器の学習ステップと判別器の学習ステップを繰り返し行います。
- 学習が進むにつれて:
- 生成器はリアルなデータを生成できるようになり、
- 判別器はそれに気づけるようになります。
- 最終的には、生成器が本物のデータ分布に非常に近いデータを生成するようになります。
収束の条件
- 理想的な状態では、生成器が完全に本物のデータを再現し、判別器はその差を識別できなくなります。
- このとき、判別器の出力 $ D(G(z)) $ は約 0.5 になります(つまり、「どちらか分からない」状態)。
実装
環境構築
conda create -n gan python=3.10
conda activate gan
pip install torch torchvision matplotlib numpy
データセットの準備
# ---------------------------
# データセットの準備 (MNIST)
# ---------------------------
mnist = datasets.MNIST(
root='./others/', # データ保存先
train=False, # False: テストデータを使用
download=False, # 既にダウンロード済みと仮定
transform=transforms.Compose([
transforms.Resize((28, 28)), # 画像サイズを 28x28 に変更
transforms.ToTensor(), # Tensor型へ変換(0~1に正規化)
transforms.Normalize([0.5], [0.5]) # 平均0.5、標準偏差0.5で正規化(-1 ~ 1 の範囲になる)
])
)
# データローダー:ミニバッチごとにデータを読み込む
dataloader = DataLoader(
dataset=mnist,
batch_size=64, # 1回のバッチで処理する画像数
shuffle=True # シャッフルして学習効率を向上
)
ネットワークの初期化
# ---------------------------
# 生成器 (Generator) の定義
# ---------------------------
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 中間層のブロック定義
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8)) # BatchNorm適用
layers.append(nn.LeakyReLU(0.2)) # 活性化関数
return layers
# ネットワーク構造
self.mean = nn.Sequential(
*block(100, 256, normalize=False), # 入力ノイズ (z): 100次元
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, 28 * 28), # 784次元の画像ベクトル
nn.Tanh() # Tanhで出力を [-1, 1] に制限
)
def forward(self, x):
imgs = self.mean(x) # ノイズから画像生成
imgs = imgs.view(-1, 1, 28, 28) # 画像形式 (batch_size, channel, height, width)
return imgs
# ---------------------------
# 判別器 (Discriminator) の定義
# ---------------------------
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.mean = nn.Sequential(
nn.Linear(28 * 28, 512), # 入力画像をフラットにする
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1), # 出力:本物かどうかの確率(Sigmoidで0~1)
nn.Sigmoid()
)
def forward(self, x):
x = x.view(-1, 28 * 28) # 画像を一次元に展開
img = self.mean(x) # 判別結果を返す
return img
# ---------------------------
# モデルのインスタンス化
# ---------------------------
generator = Generator() # 生成器のインスタンス
discriminator = Discriminator() # 判別器のインスタンス
損失関数の定義
- 損失関数は普通の二値分類問題用いる二値交差エントロピー損失関数を使う
criterion = nn.BCELoss()
学習の実行
count = len(dataloader) # ミニバッチ数
for i, (img, _) in enumerate(dataloader): # 各ミニバッチに対して
size = img.size(0) # バッチサイズ(64)
# ---------------------
# 判別器の訓練
# ---------------------
fake_img = torch.randn(size, 100) # ランダムノイズ生成
output_fake = generator(fake_img) # 偽画像生成
fake_score = discriminator(output_fake.detach()) # 勾配を切って判別
D_fake_loss = criterion(fake_score, torch.zeros_like(fake_score)) # 偽物のラベル:0
real_score = discriminator(img) # 本物画像に対する判別
D_real_loss = criterion(real_score, torch.ones_like(real_score)) # 本物のラベル:1
D_loss = D_fake_loss + D_real_loss # 判別器全体の損失
D_Apim.zero_grad() # 勾配初期化
D_loss.backward() # 逆伝播
D_Apim.step() # パラメータ更新
# ---------------------
# 生成器の訓練
# ---------------------
fake_G_score = discriminator(output_fake) # 判別器による評価
G_fake_loss = criterion(fake_G_score, torch.ones_like(fake_G_score)) # 生成器は「本物」と誤認識させたい
G_Apim.zero_grad() # 勾配初期化
G_fake_loss.backward() # 逆伝播
G_Apim.step() # パラメータ更新
# ---------------------
# 損失記録
# ---------------------
with torch.no_grad(): # 勾配計算無効
G_epoch_loss += G_fake_loss.item()
D_epoch_loss += D_loss.item()
結果の可視化

# ---------------------------
# 生成画像の可視化関数
# ---------------------------
def gen_img_plot(model, epoch, text_input):
prediction = np.squeeze(model(text_input).detach().cpu().numpy()[:16]) # 最大16枚表示
plt.figure(figsize=(4, 4))
for i in range(16):
plt.subplot(4, 4, i + 1) # 4x4のグリッドで描画
plt.imshow((prediction[i] + 1) / 2) # [-1,1] → [0,1] へ戻す
plt.axis('off') # 軸非表示
plt.show()
完全なコード
# 必要なライブラリをインポート
import torch
import torch.nn as nn
import torchvision.transforms as transforms # 前処理用
from torchvision import datasets # MNISTデータセット用
from torch.utils.data import DataLoader # データローダー
import numpy as np # 数値計算
import matplotlib.pyplot as plt # 可視化
# ---------------------------
# データセットの準備 (MNIST)
# ---------------------------
mnist = datasets.MNIST(
root='./others/', # データ保存先
train=False, # False: テストデータを使用
download=False, # 既にダウンロード済みと仮定
transform=transforms.Compose([
transforms.Resize((28, 28)), # 画像サイズを 28x28 に変更
transforms.ToTensor(), # Tensor型へ変換(0~1に正規化)
transforms.Normalize([0.5], [0.5]) # 平均0.5、標準偏差0.5で正規化(-1 ~ 1 の範囲になる)
])
)
# データローダー:ミニバッチごとにデータを読み込む
dataloader = DataLoader(
dataset=mnist,
batch_size=64, # 1回のバッチで処理する画像数
shuffle=True # シャッフルして学習効率を向上
)
# ---------------------------
# 生成画像の可視化関数
# ---------------------------
def gen_img_plot(model, epoch, text_input):
prediction = np.squeeze(model(text_input).detach().cpu().numpy()[:16]) # 最大16枚表示
plt.figure(figsize=(4, 4))
for i in range(16):
plt.subplot(4, 4, i + 1) # 4x4のグリッドで描画
plt.imshow((prediction[i] + 1) / 2) # [-1,1] → [0,1] へ戻す
plt.axis('off') # 軸非表示
plt.show()
# ---------------------------
# 生成器 (Generator) の定義
# ---------------------------
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 中間層のブロック定義
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8)) # BatchNorm適用
layers.append(nn.LeakyReLU(0.2)) # 活性化関数
return layers
# ネットワーク構造
self.mean = nn.Sequential(
*block(100, 256, normalize=False), # 入力ノイズ (z): 100次元
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, 28 * 28), # 784次元の画像ベクトル
nn.Tanh() # Tanhで出力を [-1, 1] に制限
)
def forward(self, x):
imgs = self.mean(x) # ノイズから画像生成
imgs = imgs.view(-1, 1, 28, 28) # 画像形式 (batch_size, channel, height, width)
return imgs
# ---------------------------
# 判別器 (Discriminator) の定義
# ---------------------------
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.mean = nn.Sequential(
nn.Linear(28 * 28, 512), # 入力画像をフラットにする
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1), # 出力:本物かどうかの確率(Sigmoidで0~1)
nn.Sigmoid()
)
def forward(self, x):
x = x.view(-1, 28 * 28) # 画像を一次元に展開
img = self.mean(x) # 判別結果を返す
return img
# ---------------------------
# モデルのインスタンス化
# ---------------------------
generator = Generator() # 生成器のインスタンス
discriminator = Discriminator() # 判別器のインスタンス
# ---------------------------
# オプティマイザの定義
# ---------------------------
G_Apim = torch.optim.Adam(generator.parameters(), lr=0.0001) # 生成器の最適化
D_Apim = torch.optim.Adam(discriminator.parameters(), lr=0.0002) # 判別器の最適化
# ---------------------------
# 損失関数の定義
# ---------------------------
criterion = torch.nn.BCELoss() # 二値交差エントロピー損失
# ---------------------------
# 学習ループの設定
# ---------------------------
epoch_num = 100 # エポック数
G_loss_save = [] # 生成器の損失記録
D_loss_save = [] # 判別器の損失記録
for epoch in range(epoch_num): # 繰り返し学習
G_epoch_loss = 0
D_epoch_loss = 0
count = len(dataloader) # ミニバッチ数
for i, (img, _) in enumerate(dataloader): # 各ミニバッチに対して
size = img.size(0) # バッチサイズ(64)
# ---------------------
# 判別器の訓練
# ---------------------
fake_img = torch.randn(size, 100) # ランダムノイズ生成
output_fake = generator(fake_img) # 偽画像生成
fake_score = discriminator(output_fake.detach()) # 勾配を切って判別
D_fake_loss = criterion(fake_score, torch.zeros_like(fake_score)) # 偽物のラベル:0
real_score = discriminator(img) # 本物画像に対する判別
D_real_loss = criterion(real_score, torch.ones_like(real_score)) # 本物のラベル:1
D_loss = D_fake_loss + D_real_loss # 判別器全体の損失
D_Apim.zero_grad() # 勾配初期化
D_loss.backward() # 逆伝播
D_Apim.step() # パラメータ更新
# ---------------------
# 生成器の訓練
# ---------------------
fake_G_score = discriminator(output_fake) # 判別器による評価
G_fake_loss = criterion(fake_G_score, torch.ones_like(fake_G_score)) # 生成器は「本物」と誤認識させたい
G_Apim.zero_grad() # 勾配初期化
G_fake_loss.backward() # 逆伝播
G_Apim.step() # パラメータ更新
# ---------------------
# 損失記録
# ---------------------
with torch.no_grad(): # 勾配計算無効
G_epoch_loss += G_fake_loss.item()
D_epoch_loss += D_loss.item()
# エポックごとの平均損失を保存
G_epoch_loss /= count
D_epoch_loss /= count
G_loss_save.append(G_epoch_loss)
D_loss_save.append(D_epoch_loss)
print(f'Epoch: [{epoch}/{epoch_num}] | G_loss: {G_epoch_loss:.3f} | D_loss: {D_epoch_loss:.3f}')
# ---------------------
# 生成画像の可視化
# ---------------------
text_input = torch.randn(64, 100) # 新しいノイズ
gen_img_plot(generator, epoch, text_input) # 生成画像をプロット
# ---------------------------
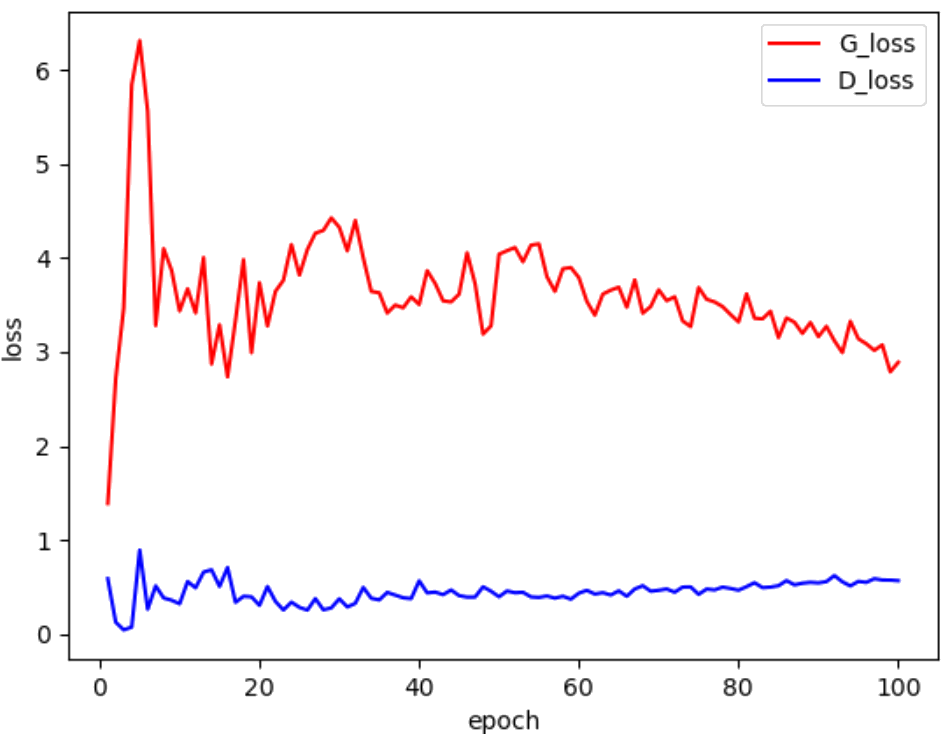
# 損失のグラフ表示
# ---------------------------
x = [epoch + 1 for epoch in range(epoch_num)]
plt.figure()
plt.plot(x, G_loss_save, 'r')
plt.plot(x, D_loss_save, 'b')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['G_loss','D_loss'])
plt.title('Training Losses')
plt.show()
トレーニングプロシースのまとめ
- 判別器の訓練:本物と偽物を見分ける能力を高める。
- 生成器の訓練:判別器をだませるようにリアルな画像を生成。
- 繰り返し更新:両ネットワークが交互に更新されながら学習。
- 可視化:生成された画像をエポックごとに確認。
- 損失グラフ:学習過程での安定性を把握。