
CNN基本建築
目次
CNN (Convolutional Neural Networks / 畳み込みニューラルネットワーク) とは、画像認識や画像分類などのコンピュータビジョンタスクで広く使用される深層学習モデルです。
基本構造
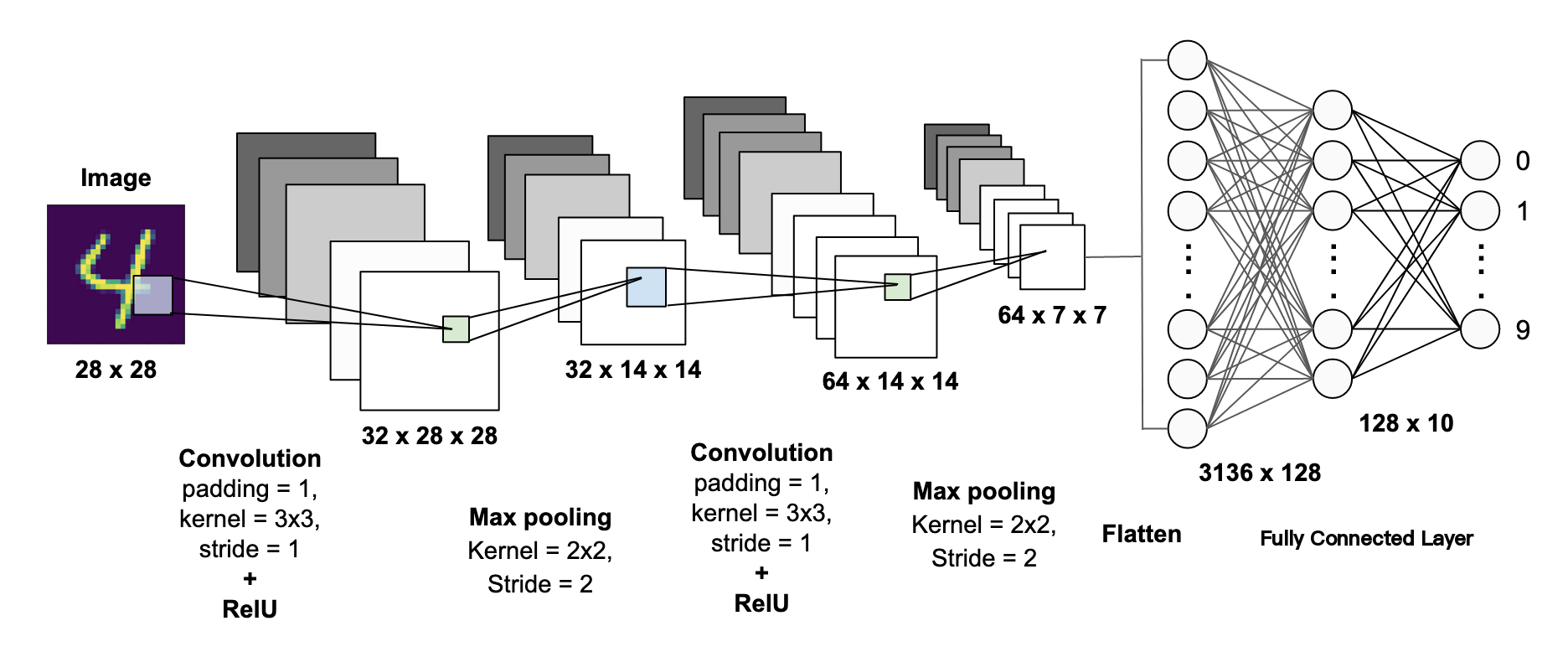
-
畳み込み層(Convolutional Layer):
- 主な役割: 特徴抽出
- 入力画像に対してフィルター(カーネル)を適用して特徴マップを作成します。
- 例: エッジ検出、形状認識など。
-
プーリング層(Pooling Layer):
- 主な役割: ダウンサンプリング
- 特徴マップのサイズを縮小し、計算量を減らすとともに過学習を防ぎます。
- 最大プーリング(Max Pooling)や平均プーリング(Average Pooling)が一般的です。
-
活性化関数(Activation Function):
- 非線形性を導入するために使用されます。
- 一般的にはReLU(Rectified Linear Unit)が使われます。
-
全結合層(Fully Connected Layer):
- 畳み込み層とプーリング層で抽出された特徴を利用して、最終的に分類を行います。
- 多層パーセプトロンとして機能します。
-
ドロップアウト層(Dropout Layer):
- 過学習を防ぐために一部のニューロンをランダムに無効化します。
入力層
コンピュータは画像を数値として処理するため、画像は次のような形式に変換されます:
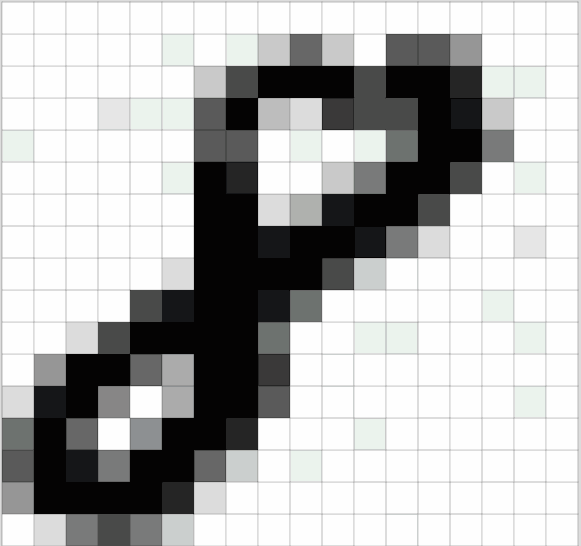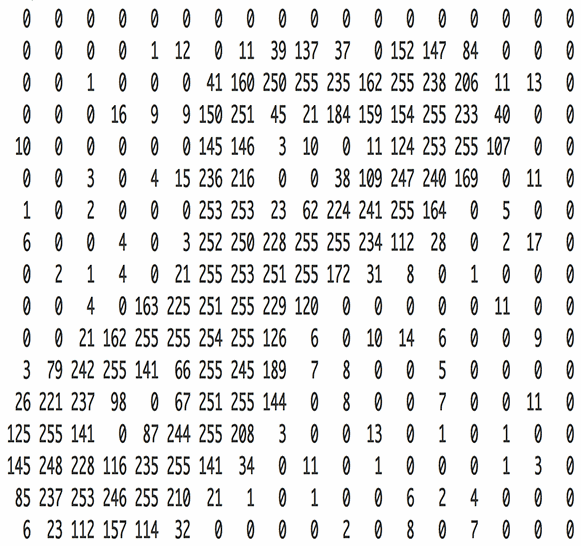
-
グレースケール画像(Gray-scale Image):
- 各ピクセルの値は0〜255の範囲で、0が黒、255が白を表します。
- 画像は2次元の行列として表現されます。
- 例:手書き数字「8」の画像は、以下のようにピクセル値の行列として表現されます。
-
二値画像(Binary Image):
- 各ピクセル値は0(黒)または255(白)のどちらかです。
- 単純なパターン認識に適しています。
-
RGB画像(カラー画像):
- 赤(R)、緑(G)、青(B)の3つのチャネルを持ち、それぞれのチャネルのピクセル値は0〜255の範囲です。
- 3次元の行列として表現されます。
- 例:画像サイズが28×28ピクセルの場合、RGB画像の行列は (28, 28, 3) となります。
畳み込み層
畳み込み層は、入力画像の2次元行列に対して**畳み込み演算(Convolution Operation)**を行い、特徴マップ(Feature Map)を生成します。この特徴マップには、画像内の特定のパターン(エッジ、角、形状など)が強調されて現れます。
畳み込み演算の手順
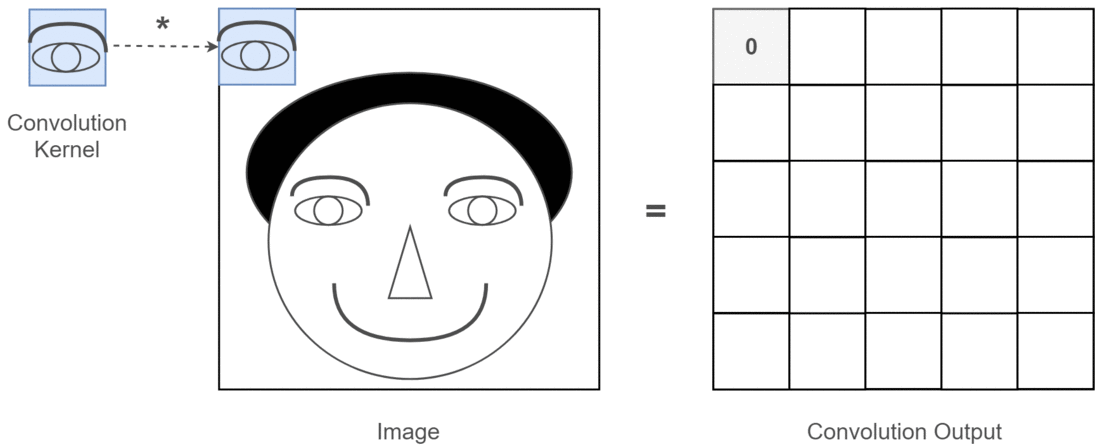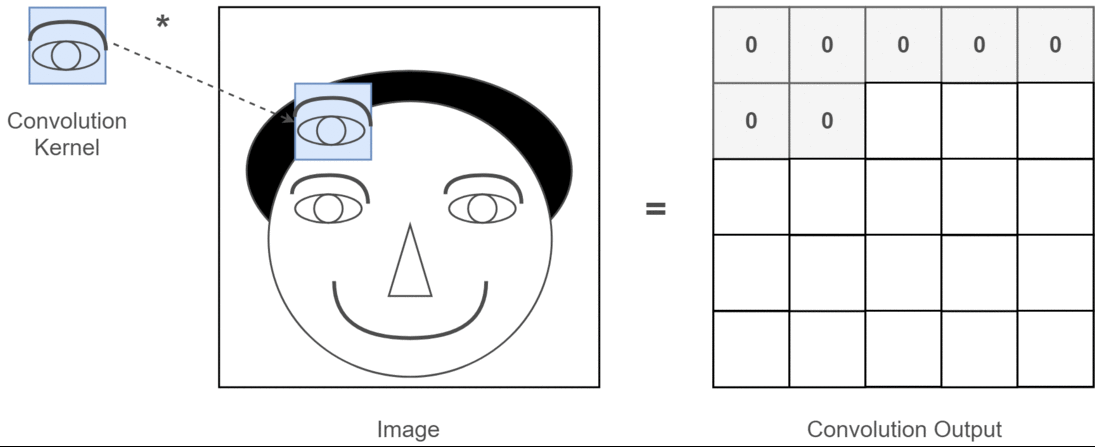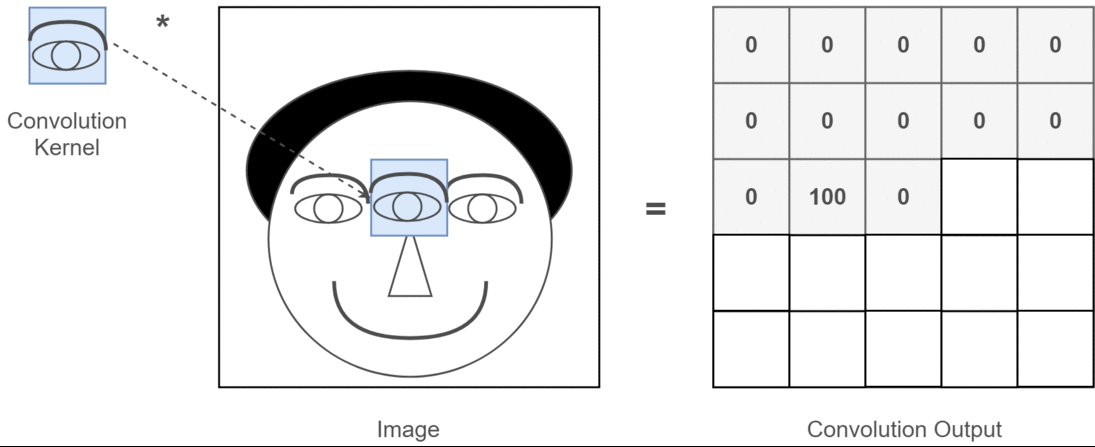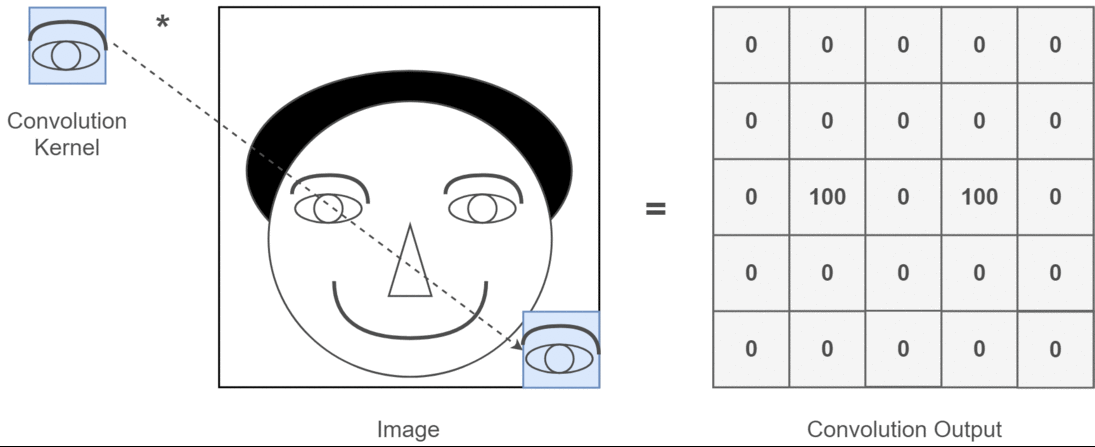
- 畳み込みカーネル(フィルター)の適用
- 畳み込みカーネル(Convolution Kernel)は小さな2次元行列で、画像の特定の特徴(例:エッジ、角)を検出するために設計されています。
- 例:カーネルのサイズは通常
3×3や5×5です。
- スライディング(移動)
- カーネルは、入力画像の2次元行列上を左上から右下に向かってスライドします(移動量はストライドと呼ばれます)。
- スライドするたびに、カーネルと対応する画像領域の要素ごとの積を計算し、総和を取ります。
- 特徴マップの生成
- 各位置での畳み込み演算の結果を結合して、新しい2次元行列(特徴マップ)を作成します。
順伝播(Forward)の数式
畳み込み演算は、入力画像 $ X $ とフィルター(カーネル) $ W $ を使って行われます。以下にその基本的な数式を示します。
- $ Y_{i,j} $:出力特徴マップの位置
(i,j)の値 X:入力画像(2次元行列)W:フィルター(カーネル)$ k \times k $b:バイアス項k:カーネルのサイズ
逆伝播では、損失関数 $ L $ の勾配をフィルター $ W $ と入力 $ X $ に対して求めます。
(1) フィルター $ W $ に関する勾配
(2) 入力 $ X $ に関する勾配
(3) バイアス $ b $ に関する勾配
パディング(Padding)
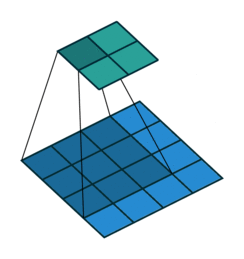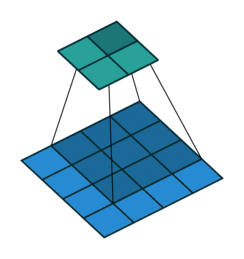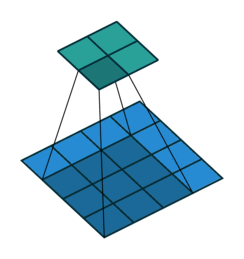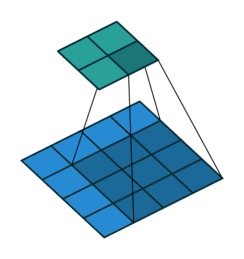
畳み込み演算では、画像の端の情報が特徴マップに反映されにくいという問題があります。これを補うために、パディングという処理が使われます。
パディングの仕組み
- 入力画像の周囲に0などの値で1層または複数層を追加します。
- これにより、画像の端の情報も特徴マップに十分に反映されます。
Padding = 1 の場合
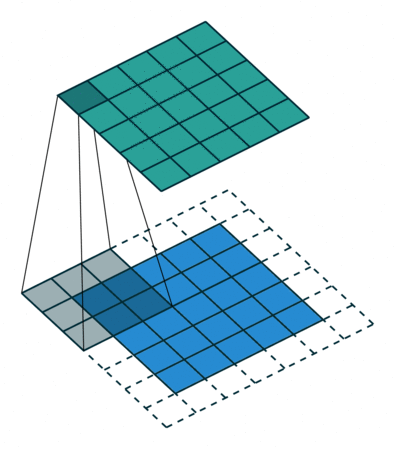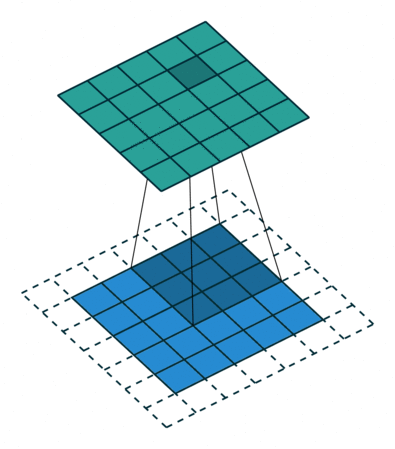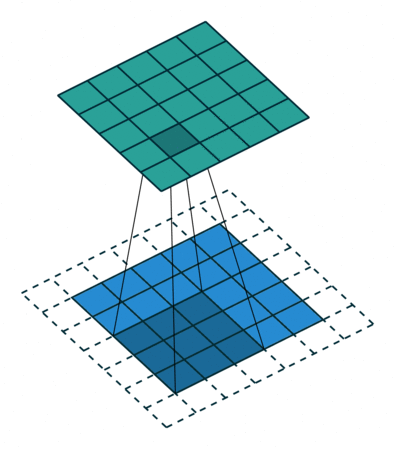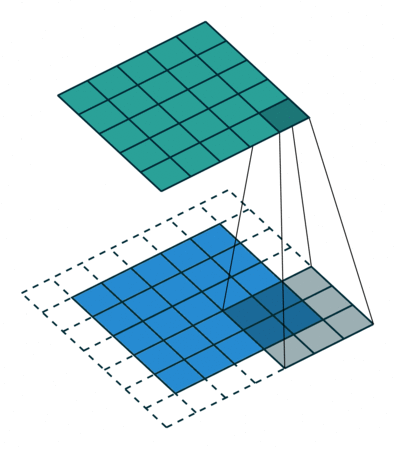
- 画像の周囲に1層の0を追加し、畳み込み演算を行います。
- これにより、特徴マップのサイズが入力画像とほぼ同じになります。
Padding = 2 の場合
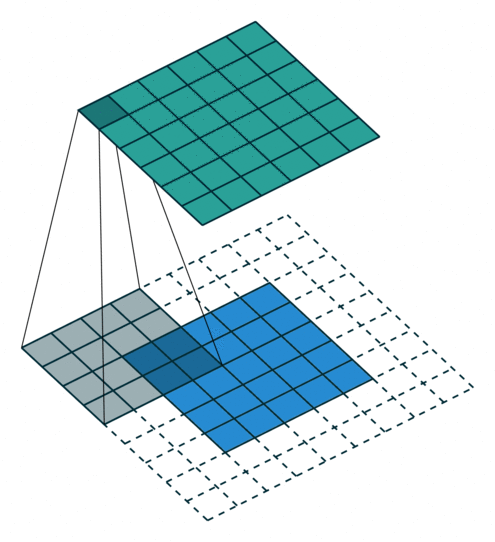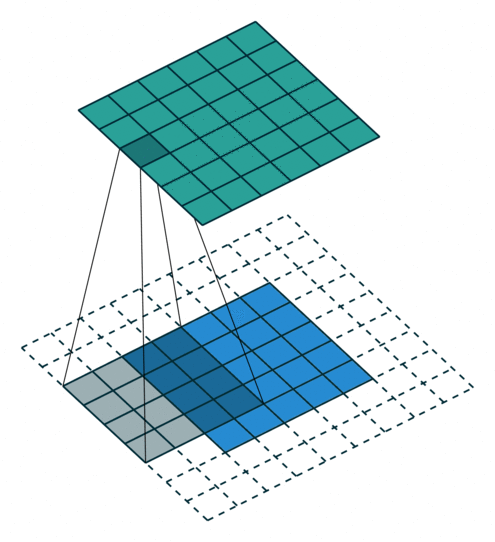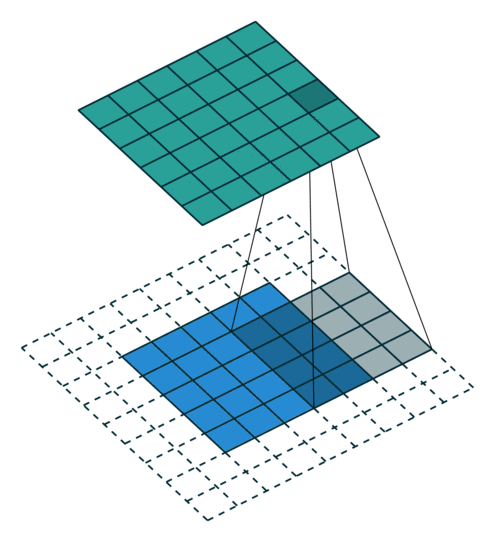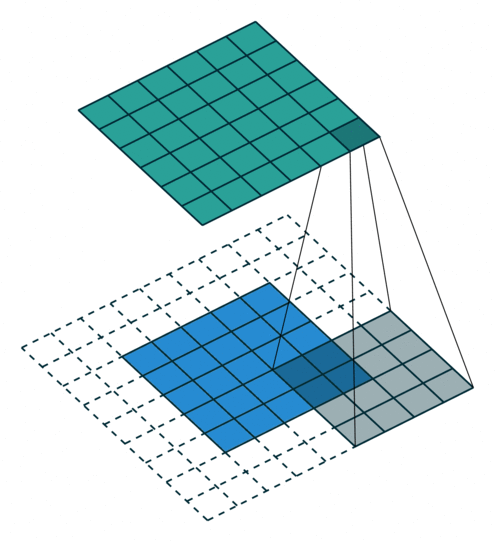
- 周囲に2層の0を追加します。
- より広範囲の端の情報を保持することができます。
多チャンネル画像の処理
カラー画像(RGB画像)のように、複数のチャンネルを持つ画像の場合、以下のように処理されます。
処理手順
- 各チャンネル(R, G, B)ごとに畳み込み演算を行います。
- 各チャンネルに対応するカーネルを使用し、それぞれで畳み込み演算を行います。
- 各カーネルの結果を足し合わせ、最終的な特徴マップを生成します。
図の説明
2つのカーネルを使用して畳み込みを行う過程
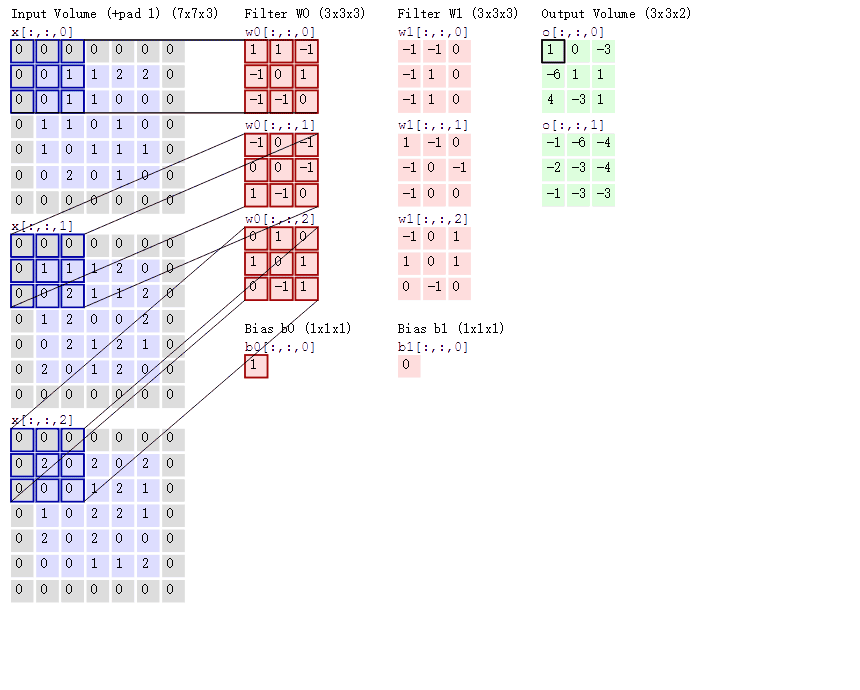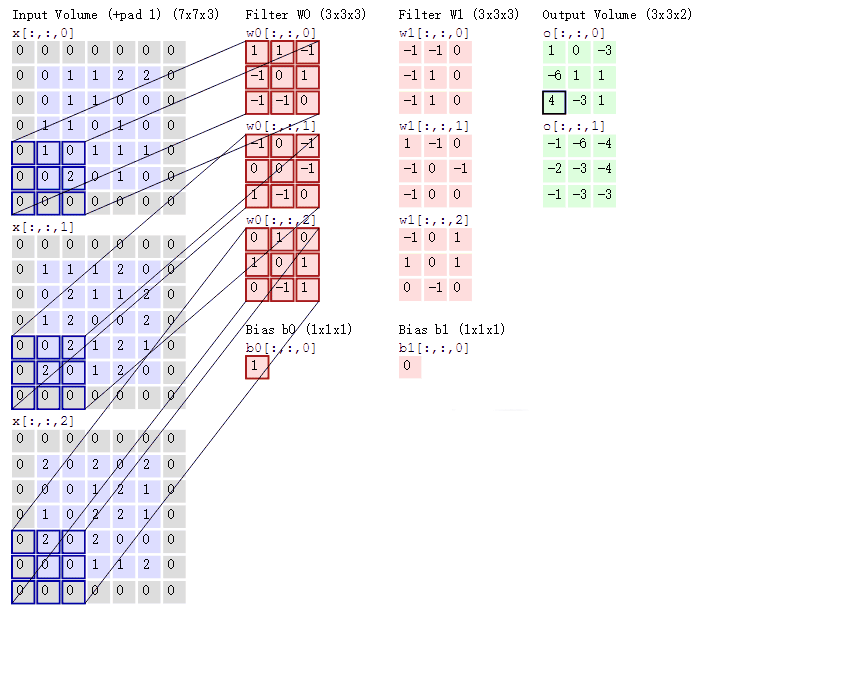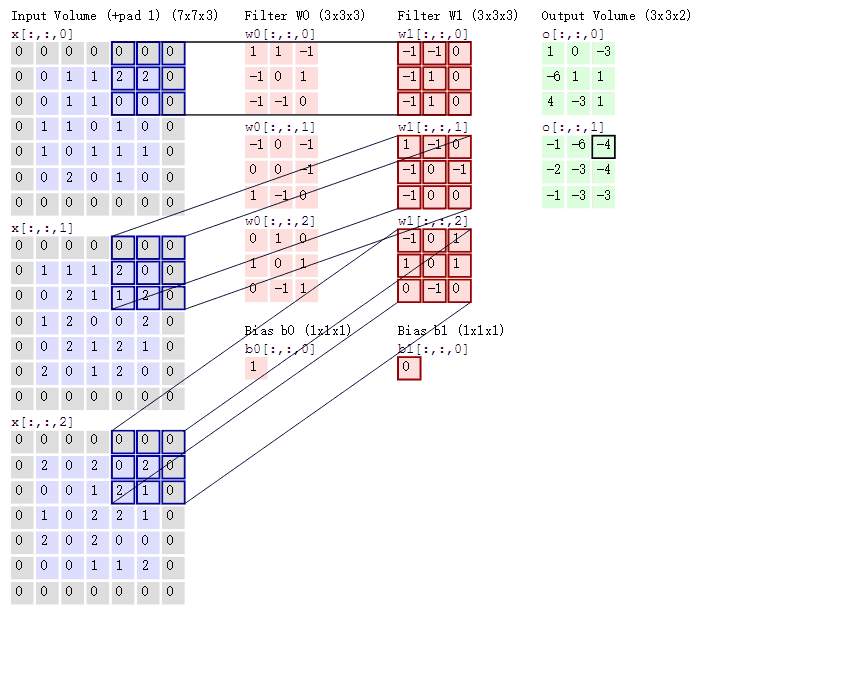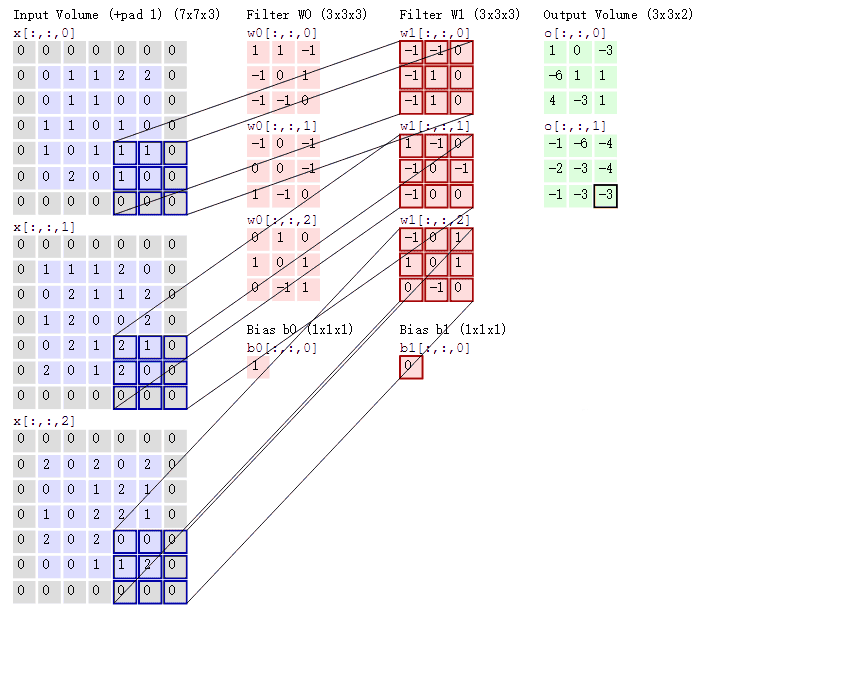
- 入力画像がRGB画像(7×7×3)であると仮定します。
- 2つのカーネルを使用して、それぞれで畳み込み演算を行い、2つの特徴マップを生成します。
- 各カーネルにはバイアス(偏置項)が含まれており、演算結果に加算されます。
プーリング層
- ダウンサンプリング(Downsampling):
- 特徴マップの解像度を下げることで、後の層での計算量を削減します。
- 位置変動へのロバスト性の向上:
- 少し位置がずれても同じ特徴が検出されるようにします。
- 過学習の防止:
- データの空間的冗長性を減らすことで、過学習を抑制します。
主なプーリング手法
最大プーリング(Max Pooling)
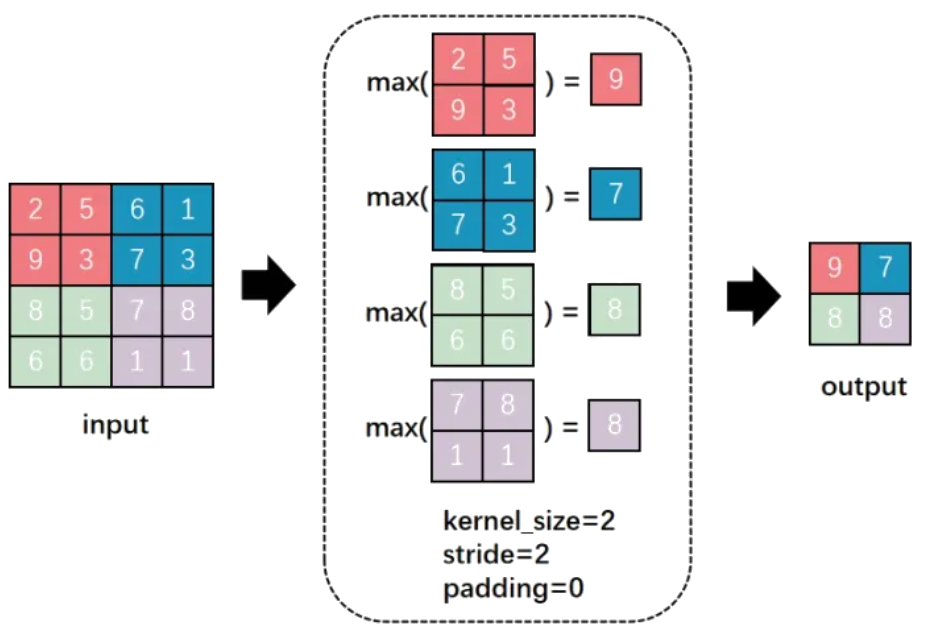
- 特徴マップの一部領域(例:2×2)から最大値を取り出す方法。
- よく使われ、エッジや重要な特徴を強調します。
数式:
- $ k $:プーリング窓のサイズ
例:
入力:
[
[2, 5, 6, 1],
[9, 3, 7, 3],
[8, 5, 7, 8],
[6, 6, 1, 1],
]
最大プーリング (2x2):
[
[9, 7],
[8, 8],
]
平均プーリング(Average Pooling)
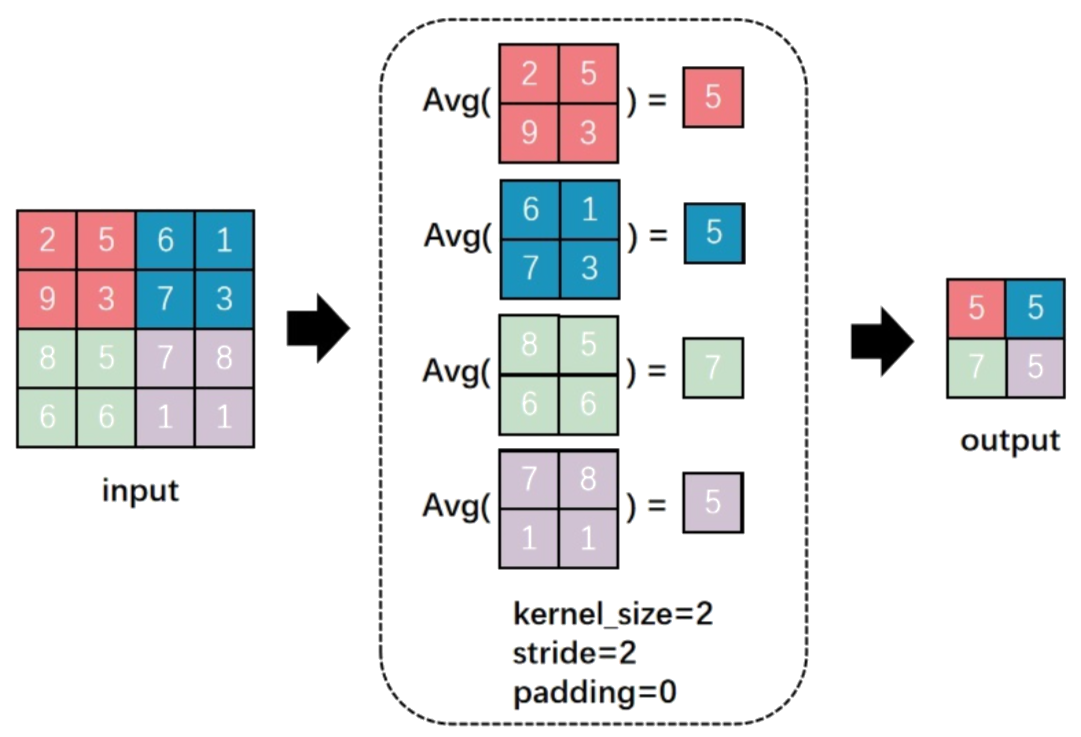
- 特徴マップの一部領域から平均値を取り出す方法。
- 最大プーリングよりも滑らかな特徴を抽出します。
数式:
例:
入力:
[
[2, 5, 6, 1],
[9, 3, 7, 3],
[8, 5, 7, 8],
[6, 6, 1, 1],
]
平均プーリング (2x2):
[
[5, 5],
[7, 5],
]
全結合層
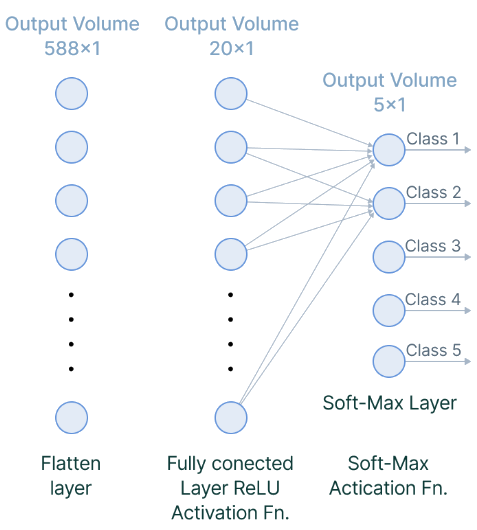
畳み込み層やプーリング層では、画像の局所的な特徴(例:目、鼻、口)が特徴マップとして抽出されます。
しかし、これらの特徴を使って「これは人の顔だ」と判断するには、すべての特徴を統合して評価する必要があります。
処理の流れ
-
展平(Flattening)
- 特徴マップを1次元のベクトルに変換します。
- 例:特徴マップが
7×7×3の場合 →1×147の1次元ベクトルに変換。
-
全結合演算
- すべての要素に対して重み(Weight)とバイアス(Bias)を使った線形変換を行います。
- 数式:
- $ X $:入力ベクトル(展平された特徴)
- $ W $:重み行列
- $ b $:バイアス
- $ Y $:出力ベクトル
-
活性化関数による非線形変換
- ReLUやSigmoid、Softmaxなどの活性化関数を使って、非線形な関係を学習します。
- 最終的には、どのクラスに属するかの確率を出力します。
まとめ
CNN(畳み込みニューラルネットワーク)
- 畳み込みニューラルネットワーク(Convolutional Neural Network)は、画像認識や画像分類などのコンピュータビジョンタスクで広く使われる深層学習モデルです。
- 主に画像データを入力として、その中に含まれる特徴を自動で抽出し、最終的に画像の分類を行います。
CNNの基本構造と各層の役割
| 層の種類 | 役割 | 特徴 |
|---|---|---|
| 入力層 | 画像をコンピュータが処理できる形式(2次元または3次元の行列)に変換 | グレースケール・RGB画像に対応 |
| 畳み込み層(Conv Layer) | 画像から特徴を抽出(例:エッジ、角、目、鼻など) | フィルター(カーネル)を使って畳み込み演算 |
| プーリング層(Pooling Layer) | 特徴マップのサイズを縮小し、計算量を減らす | 最大プーリング(Max Pooling)や平均プーリング(Average Pooling)が一般的 |
| 活性化関数(Activation) | 非線形性を導入し、複雑な関数を学習可能に | ReLUが最も一般的 |
| 全結合層(Fully Connected Layer) | 抽出されたすべての特徴を使って最終的な分類を行う | 特徴を1次元に展開し、確率を出力 |
流れ
[入力画像]
↓
[畳み込み層] → 特徴抽出
↓
[プーリング層] → 特徴の縮小とロバスト性向上
↓
[活性化関数] → 非線形性の導入
↓
[全結合層] → 最終的な分類
コード例 (AlexNet)
import torch
import torch.nn as nn
import torchvision
class AlexNet(nn.Module):
def __init__(self,num_classes=1000):
super(AlexNet,self).__init__()
self.feature_extraction = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=96,kernel_size=11,stride=4,padding=2,bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2,padding=0),
nn.Conv2d(in_channels=96,out_channels=192,kernel_size=5,stride=1,padding=2,bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2,padding=0),
nn.Conv2d(in_channels=192,out_channels=384,kernel_size=3,stride=1,padding=1,bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384,out_channels=256,kernel_size=3,stride=1,padding=1,bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,stride=1,padding=1,bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0),
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(in_features=256*6*6,out_features=4096),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.Linear(in_features=4096, out_features=num_classes),
)
def forward(self,x):
x = self.feature_extraction(x)
x = x.view(x.size(0),256*6*6)
x = self.classifier(x)
return x
if __name__ =='__main__':
# model = torchvision.models.AlexNet()
model = AlexNet()
print(model)
input = torch.randn(8,3,224,224)
out = model(input)
print(out.shape)