
Pytorch で Warm up と Cosine Annealing の組み合わせ
2023/10/21
AI
目次
Linear Warmup とは
- Linear Warmup: 学習開始時に学習率を 0 から徐々に増加させる手法。初期の大きな更新による不安定性を軽減。
なぜ Warmup が必要
- 学習初期に重みが不安定なため、大きな学習率を使うと発散しやすい
- 学習率を徐々に増加させることで、安定して収束する
コード例
import torch
from torch.optim.lr_scheduler import LambdaLR
def get_warmup_scheduler(optimizer, warmup_steps):
def lr_lambda(current_step: int):
if current_step < warmup_steps:
return float(current_step) / float(max(1, warmup_steps))
return 1.0
return LambdaLR(optimizer, lr_lambda)
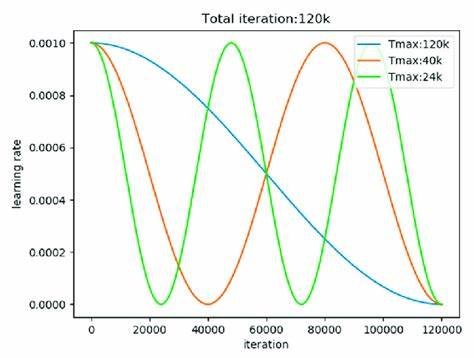
Cosine Annealing とは
- Cosine Annealing: 学習率をコサイン関数のように減少させながら最適解に近づく手法。周期的に復活させる
SGDR(Stochastic Gradient Descent with Warm Restarts)としても知られる。
基本の更新式
- : 現在のステップ数
- : 現在の周期数(整数)
- : 現在の学習率
- : 最小学習率(デフォルト: 0)
- : 初期学習率(optimizer で設定された値)
- : 現在の epoch 数 or step 数
- : 最大学習ステップ数 or エポック数(半周期)
LambdaLR で warmup と cosine annealing を組合
import math # 数学関数を利用するためのモジュール
import torch # PyTorchフレームワークをインポート
from torchvision.models import resnet18 # ResNet-18モデルをインポート
model = resnet18(pretrained=True) # 事前学習済みのResNet18モデルをロード
optimizer = torch.optim.SGD(params=[ # SGDオプティマイザを初期化し、2つのparam_groupを設定
{'params': model.layer2.parameters()}, # layer2のパラメータにはデフォルトのlr (0.1)
{'params': model.layer3.parameters(), 'lr':0.2}, # layer3のパラメータには個別のlr (0.2)
], lr=0.1) # 基本学習率 (base_lr) を0.1に設定
# warm upのイテレーション数を設定
warm_up_iter = 10
T_max = 50 # スケジューラの総イテレーション数(周期)
lr_max = 0.1 # 最大学習率
lr_min = 1e-5 # 最小学習率
# param_groups[0] (model.layer2) の学習率調整関数: Warm up + Cosine Annealing
lambda0 = lambda cur_iter: (
cur_iter / warm_up_iter
if cur_iter < warm_up_iter
else (
lr_min
+ 0.5
* (lr_max - lr_min)
* (
1.0
+ math.cos((cur_iter - warm_up_iter) / (T_max - warm_up_iter) * math.pi)
)
)
/ 0.1
)
# param_groups[1] (model.layer3) の学習率は変更しない
lambda1 = lambda cur_iter: 1
# LambdaLRを使用してカスタム学習率スケジューラを設定
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda0, lambda1])
for epoch in range(50): # 学習エポックのループ
print(optimizer.param_groups[0]['lr'], optimizer.param_groups[1]['lr']) # 現在の各param_groupの学習率を出力
optimizer.step() # オプティマイザを更新
scheduler.step() # スケジューラを更新