
AMP と Autocast
2023/10/11
AI
目次
- 目次
- Automatic Mixed Precision とは
torch.cuda.amp.autocast機能概要autocastの原理GradScalerとの併用- 利点(メリット)
- 注意点(デメリット)
- 一般的な問題と対処法
- サンプルコード
- まとめ
- 参考文献
Automatic Mixed Precision とは
デフォルトでは、ほとんどのディープラーニングフレームワークは 32 ビット浮動小数点アルゴリズムを使用してトレーニングされる。
2017 年、NVIDIA は、ネットワークをトレーニングする際に単精度(FP32)と半精度(FP16)を組み合わせ、FP32 とほぼ同じ精度を達成するために同じハイパーパラメータを使用する混合精度トレーニングの方法を研究した。
FP16 は半精度とも呼ばれ、コンピュータで使用される 2 進数の浮動小数点データ型で、2 バイトのストレージを使用する。 そして FLOAT は FP32 である。
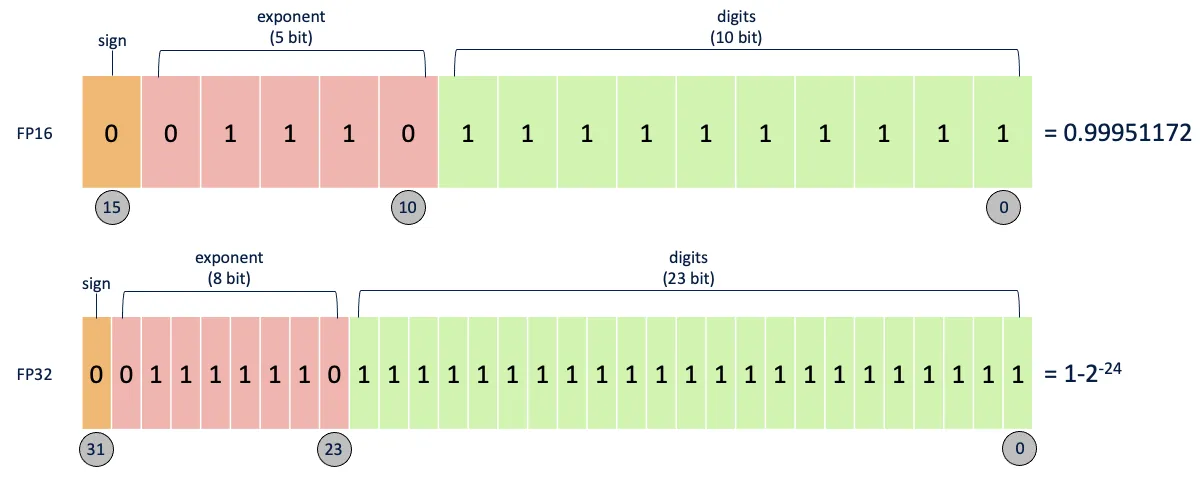
- 定義:
モデルの計算をFP32(単精度)とFP16(半精度)で効率的に切り替えて実行することで、パフォーマンス向上とメモリ削減を実現する技術。 - 目的:
- 訓練速度の向上
- GPU メモリ使用量の削減
- 数値精度の維持
torch.cuda.amp.autocast 機能概要
役割
- 推論・訓練中の演算に対して、自動的に適切な精度(FP16/FP32)を選択して実行。
- 特に数値安定性が重要な部分は FP32 を使用し、性能が重要な部分は FP16 を使用。
基本的な使い方
from torch.cuda.amp import autocast
with autocast():
output = model(input)
loss = loss_fn(output, target)
autocast の原理
-
内部処理フロー:
- 算子呼び出し時に、入力テンソルの型に基づいて自動で精度変換。
- FP16 で安全な演算のみ実行、不安定な演算は FP32 で実行。
- 出力は必要に応じて元の精度に戻す。
-
適用範囲:
- 多くの PyTorch 演算が対象。
- GPU でのみ利用可能(CUDA サポートが必要)。
GradScaler との併用
なぜ必要か
- FP16 では勾配消失や inf/nanが発生しやすいため、数値安定性を確保するために使用。
- 勾配を一定倍率(scale)で拡大して保存し、更新前に縮小。
使用方法
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for data, target in dataloader:
optimizer.zero_grad()
with autocast(): # 自動精度変換を有効化する。
output = model(data)
loss = loss_fn(output, target)
scaler.scale(loss).backward() # 自動精度変換と勾配スケーリングを行う。
scaler.step(optimizer) # 勾配を更新する。
scaler.update() # 勾配スケーリングを更新する。
利点(メリット)
| 項目 | 内容 |
|---|---|
| 高速化 | FP16 演算により、特に NVIDIA Ampere アーキテクチャ以降の GPU で顕著に高速化。 |
| メモリ削減 | 半精度使用により、モデルサイズやバッチサイズの上限が緩和。 |
| 自動管理 | 手動でのデータ型指定不要で、開発負荷が軽減される。 |
| 精度保持 | クリティカルな演算は FP32 で行われるため、精度低下が最小限。 |
注意点(デメリット)
| 問題点 | 対応策 |
|---|---|
| ハードウェア依存 | FP16 対応 GPU(例: NVIDIA Volta 以降)が必要。 |
| NaN/Inf 問題 | GradScaler を使用して勾配スケーリングを行う。 |
| 特定演算の非対応 | 一部の演算は FP16 未対応の場合あり(ドキュメント参照)。 |
| デバッグ難易度 | 精度が自動選択されるため、中間出力の確認が複雑化する場合あり。 |
一般的な問題と対処法
Loss が NaN になるケース
- 原因:
- FP16 による数値誤差
- log(0) や除算ゼロなど数学的エラー
- 解決策:
GradScalerを必ず併用- 安全な値で clamp(例:
x.clamp(min=1e-8))
モデルが深すぎて勾配消失
- 対処法:
- 層ごとの勾配クリッピング
- 活性化関数や正則化手法を見直し
サンプルコード
基本的な AMP 訓練ループ
from torch.cuda.amp import autocast, GradScaler
model = MyModel().cuda()
optimizer = torch.optim.Adam(model.parameters())
scaler = GradScaler()
for epoch in range(epochs):
for inputs, targets in dataloader:
inputs, targets = inputs.cuda(), targets.cuda()
optimizer.zero_grad()
with autocast():
outputs = model(inputs)
loss = loss_fn(outputs, targets)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
まとめ
| 項目 | 内容 |
|---|---|
| AMP | FP32 と FP16 を自動で切り替える技術 |
| autocast | 自動で演算精度を最適化するコンテキストマネージャー |
| GradScaler | FP16 勾配のスケーリングを行い、数値不安定性を回避 |
| 推奨環境 | NVIDIA GPU(Volta 以降)、CUDA 対応アプリケーション |
| 主な利点 | パフォーマンス向上、メモリ節約、自動管理による簡潔さ |
| 注意点 | NaN/Inf 問題、一部演算の FP16 非対応、デバッグの複雑化 |