
pytorchで並列的に学習を行う方法
目次
並列の種類
1 台のマシンに 1 枚のカードの場合、情報はすべて 1 台のマシンにあり、分散はない。
分散トレーニングでは、情報は「分散」され、その分散の仕方の違いを「並列性」と呼ぶことが多い。 通常、分散は「データ並列」(Data Parallelism)と「モデル並列」(Model Parallelism)に分類されるのが通例である。
データ並列
データ並列処理では、サンプルデータはスライスされ、スライスされたデータは各トレーニングノードに送られ、そこで完全なモデルに対して実行され、複数のノードからの情報がマージされる。
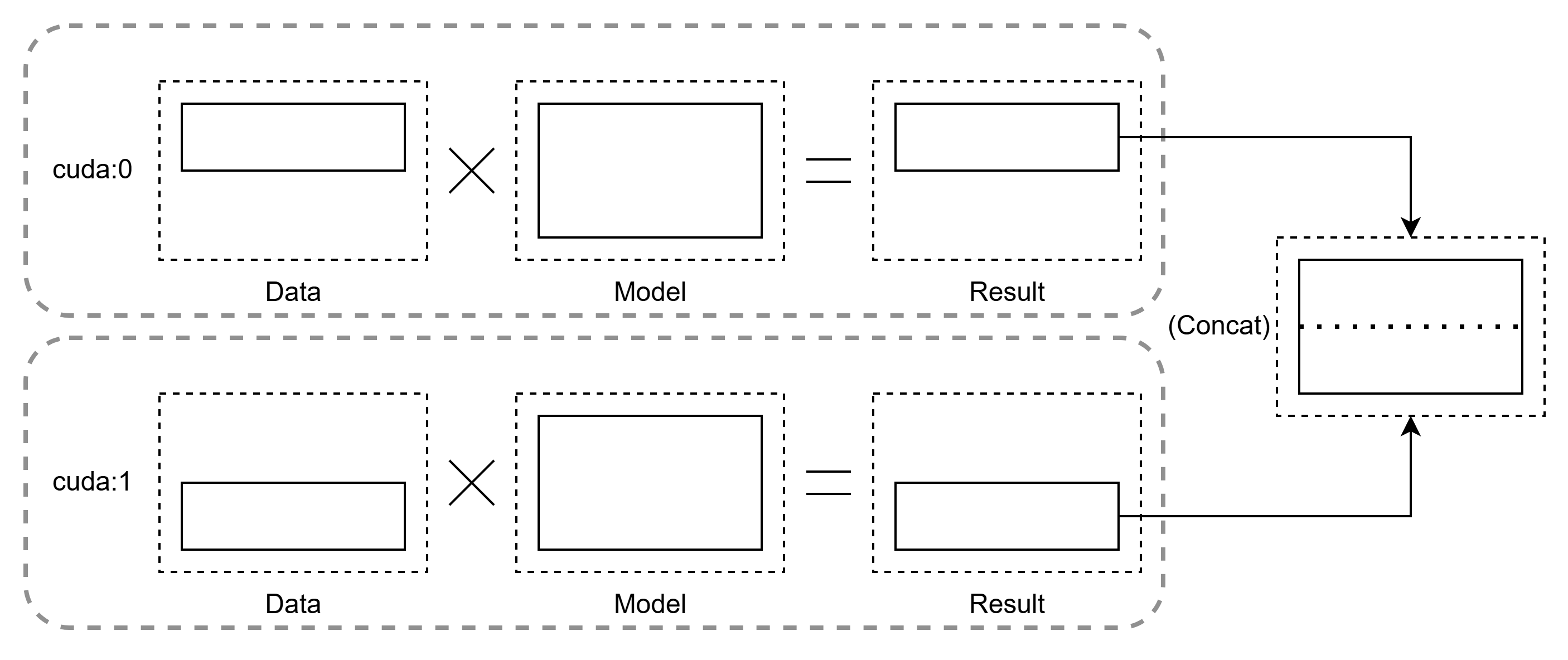
GPU の観点から説明すると、各 GPU に同じ構造のモデルを複製し、入力データをミニバッチ単位で分割して並列処理します。その後、各 GPU で計算された勾配を統合・同期することで、全体の学習を進めます。
具体的な手順は以下の通りです:
- データ分割:CPU が各 GPU に異なるミニバッチデータを配布。
- 並列計算:各 GPU でモデルの順伝播・逆伝播を独立して実行。
- 勾配同期:各 GPU 間で勾配を収集(AllReduce)し、パラメータを更新。
なぜデータ並列が必要か
- 訓練速度の加速:データ量が増加するにつれて、単一 GPU では訓練時間が過長になるため、複数 GPU で分散処理することで線形近似の高速化を実現します。
- リソース効率化:大規模データセット(例:ImageNet)や複雑なモデル(例:ResNet50)において、限られたハードウェアリソースで効率的な学習を可能にします。
線形加速比の具体例
前提条件:
- データセット:128 万枚の ImageNet 画像
- モデル:ResNet50
- 単 GPU の最大バッチサイズ:128
- 1 バッチ処理時間:7.2 秒(前処理+順伝播+逆伝播)
計算:
- 1 エポックの処理時間:
128万枚 ÷ 128 = 1万バッチ→1万 × 7.2秒 = 72,000秒(20時間) - 100 エポックの総時間:
20時間 × 100 = 2000時間(約83日)
分散環境での比較:
- 単一 GPU の場合:約 3 か月(非現実的)
- 4 台 ×8GPU(計 32GPU)の場合:線形加速比を仮定すると、
2000時間 ÷ 32 = 62.5時間(約2.6日)に短縮されます。
実際の課題
理論的な線形加速比(N 倍の GPU で N 倍速)は理想状態であり、実際には以下のような要因で性能が低下します:
- 通信オーバーヘッド:GPU 間の勾配同期にかかる時間
- 負荷不均衡:データ分割や計算リソースの非効率
- フレームワーク設計:PyTorch の
DistributedDataParallelなど、実装方式の影響
モデル並列
モデル並列では、モデルはスライスされ、完全なデータが各トレーニングノードに送られ、そこでスライスされたモデルに対して実行され、複数のノードからの結果がマージされる。
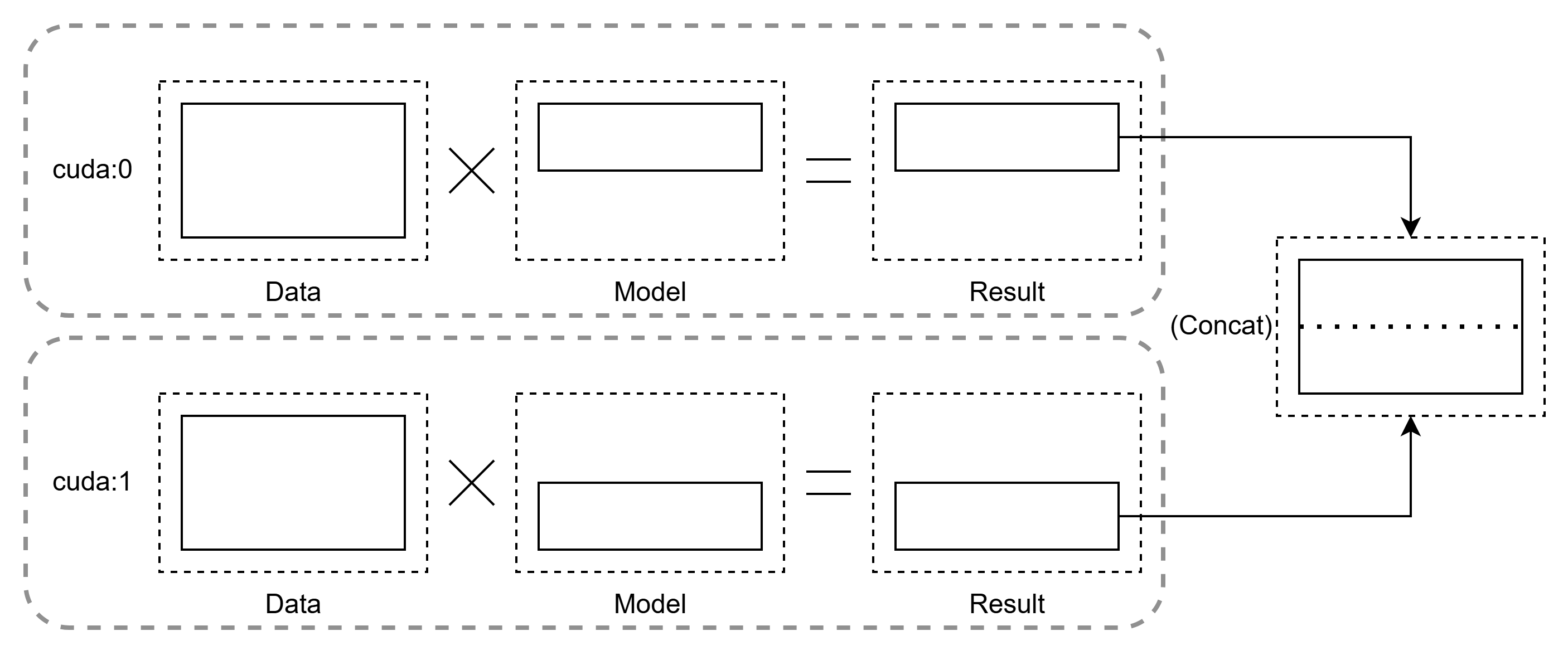
GPU の観点から説明すると、モデルの各層(または一部のパラメータ行列)を異なる GPU に配置し、データを順番に処理します。具体的な手順は以下の通りです:
- モデル分割:全体のモデルを GPU0 と GPU1 に分けて配置(例:前半層 →GPU0、後半層 →GPU1)。
- 順伝播処理:ミニバッチデータが GPU0 で処理され、その出力結果が GPU1 に送られてさらに処理される。
- 逆伝播処理:GPU1 で損失を計算し、勾配を GPU0 に伝播してパラメータ更新を行う。
なぜモデル並列が必要か?
- メモリ制約の解消:モデルが非常に大きい場合(例:クラス数が膨大な分類タスクで全結合層 FC のパラメータ量が過剰)、単一 GPU の VRAM(ビデオ RAM)ではモデルを保持できないため、複数 GPU に分割して配置する必要があります。
- スケーラビリティの向上:データ並列では対応できない超大規模モデル(例:GPT-3 など)の学習を可能にします。
具体例
前提条件:
- モデル構造:非常に深いニューラルネットワーク(全結合層のパラメータ量が過大)。
- 単 GPU の VRAM 容量:限界があるため、モデル全体を 1 枚の GPU に載せられない。
処理の流れ:
- GPU0 の処理:入力データを前半層で変換。
- 中間データの転送:GPU0→GPU1 に中間結果を送信。
- GPU1 の処理:後半層で最終出力を計算し、損失を逆伝播。
- 勾配の伝播:GPU1→GPU0 に勾配を送り、各 GPU でパラメータ更新。
分布式計算と集合通信概要
分散型ディープラーニングフレームワークでは、複数の GPU/ノード間での効率的な通信がパフォーマンスの鍵を握ります。主な基盤ライブラリは以下の 3 つに分類されます:
- 集合通信ライブラリ(例:Open MPI、NCCL、Gloo)
- 分散トレーニング時の GPU/ノード間通信を担う。
- データロード・前処理ライブラリ(例:NVIDIA DALI)
- 大規模データセットの高速読み込み・処理を最適化。
- 分散通信スケジューラーライブラリ(例:Horovod)
- MPI/NCCL/Gloo をラップし、PyTorch/TensorFlow などに統一インターフェースを提供。
集合通信(Collective Communication)の基礎
集合通信は、複数プロセス間での一括通信を実現する仕組みです。MPI(Message Passing Interface)規格で定義される主要な操作は以下の通りです:
代表的な通信操作
| 操作名 | 説明 | 使用例 |
|---|---|---|
| Broadcast | 1 つのノードのデータを全ノードに配布(1 対 N) | モデル初期重みの同期 |
| Scatter | 1 ノードのデータを分割して各ノードに配布 | ミニバッチデータの分散 |
| Gather | 全ノードのデータを 1 ノードに集約 | 分散結果の収集 |
| Reduce | 全ノードのデータを演算(SUM/MAX など)して 1 ノードに集約 | 勾配の総和計算 |
| Allreduce | 全ノードのデータを演算後、全ノードに結果を配布(Reduce + Broadcast) | 分散トレーニングでの勾配同期 |
| Allgather | 全ノードのデータを全ノードに配布 | 分散データの共有 |
Allreduce の重要性
データ並列トレーニングでは、各 GPU で計算された勾配を総和(SUM)して全ノードに同期する必要があり、これが Allreduce 操作で実現されます。
例:
- 各 GPU でローカル勾配を計算
- Allreduce で総和を取得
- 全 GPU で同一の更新済みモデルを保証
主要集合通信ライブラリの特徴
Open MPI
- HPC(ハイパフォーマンスコンピューティング)分野の標準 MPI 実装
- 学術・産業界の共同開発で高性能な通信を提供。
- 多様なハードウェア(CPU/GPU)とネットワーク(InfiniBand/Ethernet)に対応。
NCCL(NVIDIA Collective Communications Library)
- NVIDIA GPU 最適化型ライブラリ
- PCIe/NVLink 高速バスを活用し、高帯域幅・低遅延を実現。
- Allreduce/Allgather/Broadcast などの基本操作を GPU 向けに最適化。
- 主な用途:
- PyTorch/TensorFlow の分散トレーニングバックエンドとして利用可能。
- NVIDIA DGX シリーズやクラウド GPU インスタンスで高パフォーマンスを発揮。
Gloo(Facebook 開発)
- 機械学習特化の集合通信ライブラリ
- CPU/GPU 両対応で、Barrier/Broadcast/Allreduceをサポート。
- ユーザーレベルの柔軟性が高く、軽量な実装で組み込みに適す。
Horovod(分散トレーニングの共通レイヤー)
- 複数フレームワーク(PyTorch/TensorFlow/MXNet)に対応
- Open MPI/NCCL/Gloo をラップし、統一インターフェースを提供。
- Allreduce 性能の最適化と、学習コードの簡潔化を実現。
- フレームワークの差異を吸収し、分散設定を容易にします。
## pytorch 並列計算
データ並列
pytorch には、分散学習の実現方法として DataParallel と DistributedDataParallel(DDP)があります。
DataParallel
- DP(DataParallel) は 単一マシン 内で複数 GPU を使用するための並列化手法。
- シングルプロセス・マルチスレッド で動作し、Python の GIL(グローバルインタプリタロック) に制限される。
- データ並列 を実現するが、分散訓練(マルチノード)には対応しない。
DataParallel の計算手順
- 入力データの分散(Scatter)
- 主 GPU(GPU0) から各 GPU にミニバッチデータを配布。
- モデルの複製(Replication)
- 主 GPU のモデルを全 GPU に複製(各 GPU に同じ構造のモデルを配置)。
- 順伝播(Forward Pass)
- 各 GPU で独立して順伝播を実行し、出力結果(
outputs)を生成。
- 各 GPU で独立して順伝播を実行し、出力結果(
- 出力の収集(Gather)
- 各 GPU の出力を主 GPU に集約。
- 損失計算(Loss Calculation)
- 主 GPU で損失関数(
loss)を計算し、損失の勾配(loss.grad)を取得。
- 主 GPU で損失関数(
- 損失の分散(Scatter)
- 損失の勾配を各 GPU に再分散。
- 逆伝播(Backward Pass)
- 各 GPU で独立して逆伝播を実行し、パラメータの勾配(
grad)を計算。
- 各 GPU で独立して逆伝播を実行し、パラメータの勾配(
- 勾配の収集(Gather)
- 各 GPU の勾配を主 GPU に集約。
- パラメータ更新(Optimizer Step)
- 主 GPU で勾配を平均化し、モデルの重みを更新。
- モデルの同期(Broadcast)
- 更新後のモデルを全 GPU にブロードキャスト。
このプロセスをエポック数分繰り返します。
通信ステップの詳細
DP では 1 回のトレーニングステップで 4 回の通信 が発生:
- 出力収集:各 GPU の順伝播出力を主 GPU に集約(
Gather)。 - 損失分散:主 GPU の損失勾配を各 GPU に分散(
Scatter)。 - 勾配収集:各 GPU の勾配を主 GPU に集約(
Gather)。 - モデル同期:更新済みモデルを全 GPU にブロードキャスト(
Broadcast)。
DistributedDataParallel
DDP (DistributedDataParallel) は 複数マシン での分散学習を実現する手法。性能を最適化するために、DDP では全減算処理についてより詳細な設計が行われている。 勾配計算プロセスとプロセス間通信プロセスは、それぞれ一定の時間を消費します。 DDP のバックエンドにおける通信は、CPP によって記述された様々なプロトコルでサポートされており、プロトコルによって通信オペレータのサポートが異なるため、開発時の要件に応じて選択することができます。
DDP の基本構造
- マルチプロセス・マルチスレッド
- 各 GPU に専用プロセスを割り当て、Python の GIL(グローバルインタプリタロック)を回避。
- マルチノード(複数マシン)およびシングルマシンでの分散学習に対応。
- 通信方式
- AllReduce を利用した分散型同期(勾配総和)を実現。
- NCCL/Gloo/Open MPI などの集合通信ライブラリをバックエンドとしてサポート。
DDP の訓練プロセス
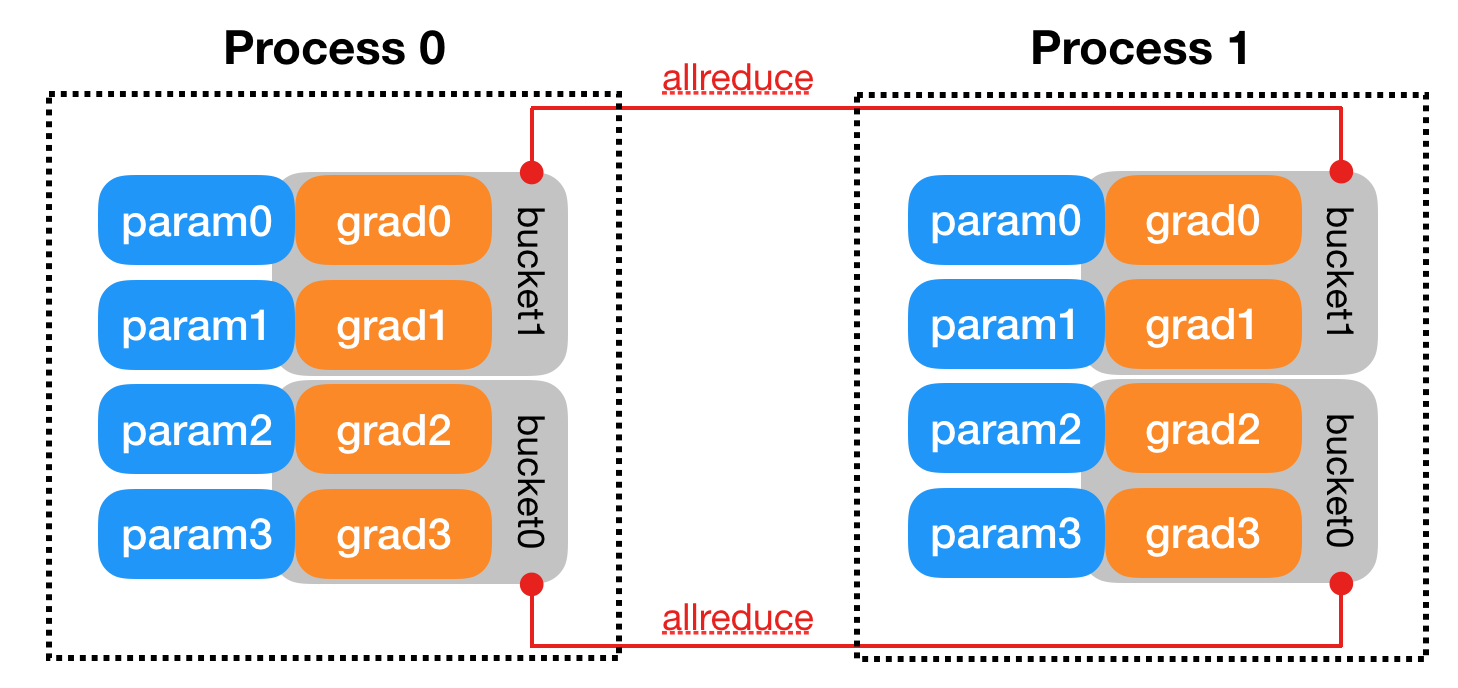
- 初期化
rank=0のプロセスからモデルパラメータを全プロセスにブロードキャスト(初期重み同期)。
- データロード
- 各プロセスがローカルデータをロード(
DistributedSamplerでデータ分割)。
- 各プロセスがローカルデータをロード(
- 順伝播(Forward Pass)
- 各 GPU で独立して順伝播を実行。
- 逆伝播(Backward Pass)
- 各 GPU で勾配を計算。
- 勾配同期(AllReduce)
- 勾配を全プロセス間で総和計算(AllReduce)。
- パラメータ更新
- 各プロセスが独立してパラメータを更新(全プロセスで同一の勾配を使用)。
DP と DDP の区別
以下に DP(DataParallel)と DDP(DistributedDataParallel)の主な違いを表形式でまとめます。
| 特徴 | DP(DataParallel) | DDP(DistributedDataParallel) |
|---|---|---|
| プロセス構造 | シングルプロセス・マルチスレッド (GIL の制約あり) |
マルチプロセス (各 GPU に独立したプロセス、GIL の影響なし) |
| 通信方式 | 集中型同期 (勾配を GPU0 に集約 → パラメータ更新 → 全 GPU にブロードキャスト) |
分散型同期 (AllReduce で勾配を総和 → 全プロセスに直接同期) |
| 通信コスト | GPU 数に比例して増加(線形スケーリング) | 固定通信コスト(Ring-AllReduce や NCCL による最適化) |
| データ転送ステップ | 4 回の通信: 1. 出力収集(Gather) 2. 損失分散(Scatter) 3. 勾配収集(Gather) 4. パラメータ同期(Broadcast) |
1 回の通信: 勾配の AllReduce(逆伝播後の勾配同期のみ) |
| マルチノード対応 | 非対応(シングルマシン限定) | 対応(シングル/マルチノード両方で利用可能) |
| ハイブリッド並列性 | データ並列のみ | モデル並列との併用が可能(例:DDP + モデル並列) |
| メモリ効率 | 無(冗長なモデルコピーが発生) | 有(勾配バケット化による効率化) |
| パラメータ更新 | GPU0 で勾配平均 → 主カードで更新 → 全 GPU にパラメータ同期 | 各プロセスで勾配 AllReduce 後、独立して更新 (初期パラメータは一度だけ同期) |
| スケーラビリティ | 不良(GPU 数増加に伴うオーバーヘッド) | 優秀(固定オーバーヘッドで大規模クラスタに適応) |
| 実装用途 | シングルマシンでのプロトタイピング (現在は非推奨) |
大規模分散訓練(現行推奨) |
補足説明
-
DP の欠点:
- 通信コストが GPU 数に比例して増加(例:8GPU 時、4 回のデータ転送が必要)。
- GIL による CPU ボトルネックと、主カード(GPU0)の負荷集中。
-
DP の利点:
- シングルマシンでの簡易検証や、初期開発が容易。
-
DDP の利点:
- AllReduce による効率的な勾配同期(例:NCCL の高帯域幅利用)。
- モデル並列との組み合わせで超大規模モデル(GPT-3 など)の学習が可能。
- 各プロセスが独立してパラメータ更新するため、負荷不均衡が解消される。
-
現在のトレンド:
DDP が PyTorch の公式推奨手法であり、大規模分散訓練には必須。DP はシングルマシンでの簡易検証に限定される。