
Transformer
Transformer は、RNN や CNN を用いたモデルの代わりに、Attention を用いたモデルです。
目次
- 目次
- Attention
- Casual Mask
- Multi-Head Attention
- FNN
- Positional Encoding
- Encoder-Decoder architecture
- Transformer
Attention
- Attention は、ある入力の特徴量が特定の出力の特徴量にどれだけ関連しているかを学習するメカニズムです。これは、シーケンスデータ(例えば、文章や音声)の処理において非常に重要な役割を果たします。
基本的な概念
- Query (Q): 出力の特徴量を表します。
- Key (K): 入力の特徴量を表します。
- Value (V): 入力の特徴量に関連する情報を表します。
- softmax: ソフトマックス関数
Attention の計算式
元の論文に、Attention は"Scaled Dot-Product Attention"
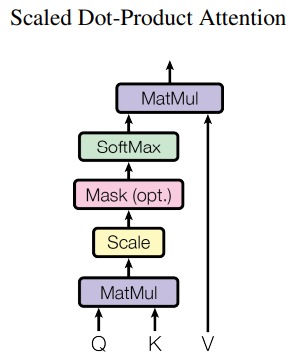
計算式の仕組み
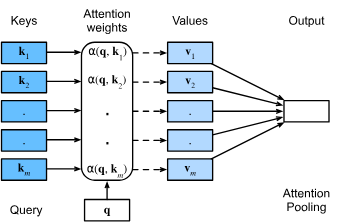
Query,Key,Value の計算
入力データから Query, Key, Value を計算します。通常、これらは線形変換(行列乗算)によって生成されます。
Attention スコアの計算
Query と Key の間の関連性を計算します。これは一般的に内積(Dot Product)を使用して行われます。
スケーリングと正規化
Attention Score (scaled):
softmax 正規化:
Attention スコアはスケーリング(通常は Key の次元数の平方根で割る)と正規化(ソフトマックス関数を適用)によって調整されます。
重み付き和の計算
Attention Weights を Value に適用し、重み付き和を計算します。
### コード
import torch
import torch.nn as nn
import torch.nn.functional as F
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
attn = self.dropout(F.softmax(attn, dim=-1))
output = torch.matmul(attn, v)
return output, attn
Casual Mask
エンコーダーでは、全ての位置の情報が利用できますが、デコーダーでは未来の位置の情報が利用できないようにするため、因果掩码が使用されます。
因果掩码は、未来の位置のスコアを に設定し、Softmax 後の重みを 0 にします。
Multi-Head Attention
Multi-Head Attention は、複数の Head を結合したものを表します。
- ここで、Head の数はです。
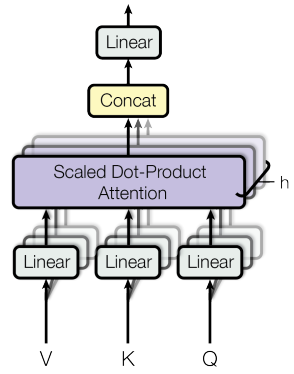
コード
import torch.nn as nn
import torch.nn.functional as F
def causal_mask(seq_len):
# return tensor with size [seq_len, seq_len], masking all the future tokens
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
return mask
class MaskedMultiHeadAttention(nn.Module):
''' Multi-Head Attention implementation in PyTorch '''
def __init__(self, emb_size, num_heads):
super().__init__()
assert emb_size % num_heads == 0
self.num_heads = num_heads
self.head_dim = emb_size // num_heads
self.qkv = nn.Linear(emb_size, emb_size * 3)
self.fc_out = nn.Linear(emb_size, emb_size)
def forward(self, x): # x: [B, T, emb]
B, T, E = x.shape
qkv = self.qkv(x) # [B, T, 3*E]
q, k, v = qkv.chunk(3, dim=-1)
# Multi Head
q = q.view(B, T, self.num_heads, self.head_dim).transpose(1, 2)
k = k.view(B, T, self.num_heads, self.head_dim).transpose(1, 2)
v = v.view(B, T, self.num_heads, self.head_dim).transpose(1, 2)
# Attention Score
scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5)
# add casual mask
mask = causal_mask(T).to(scores.device)
scores = scores.masked_fill(mask.unsqueeze(0).unsqueeze(0), float('-inf'))
attn = torch.softmax(scores, dim=-1)
out = attn @ v # [B, heads, T, head_dim]
out = out.transpose(1, 2).contiguous().view(B, T, E)
return self.fc_out(out), attn
FNN
FNN(Feed-Forward Network)は、入力から出力を計算する非線形関数です。
入力の次元数は、入力と出力の次元数に等しい必要があります。
Positional Encoding
Transformer モデルは、再帰や畳み込みを使用しないため、モデルがシーケンスの順序を利用できるように位置情報を組み込む必要があります。そのため、エンコーダとデコーダのスタックの入力埋め込みに “位置エンコーディング” を追加します。位置エンコーディングは、埋め込みと同じ次元 $ d_{\text{model}} $ を持つため、二つを足し合わせることができます。
位置エンコーディングには学習型と固定型の選択肢がありますが、この研究では正弦とコサイン関数を使用します。これらの関数は異なる周波数を持ちます:
- は偶数次元の位置エンコーディング
- は奇数次元の位置エンコーディング
- はシーケンス内の位置
- は次元のインデックス
- はモデルの次元数(通常は 512 など)
ここで、$ \text{pos} $ は位置、$ i $ は次元です。つまり、位置エンコーディングの各次元は異なる周波数を持つ正弦波に対応します。波長は $ 2\pi $ から $ 10000 \cdot 2\pi $ までの幾何級数を形成します。
この関数を選択した理由は、モデルが相対的な位置に簡単に注意を向けることができると仮定したからです。任意の固定オフセット $ k $ に対して、$ \text{PE}\text{({pos}+k)} $ は $ \text{PE}{({pos})} $ の線形関数として表現できるためです。
また、学習型位置エンコーディングも試しましたが、両バージョンの結果はほぼ同じでした。正弦関数を選択した理由は、モデルが訓練中に見なかったよりも長いシーケンス長に外挿できる可能性があるためです。
Encoder-Decoder architecture

-
エンコーダは可変長入力シーケンスを固定次元の状態ベクトルに変換
-
デコーダはエンコードされた状態と生成済みトークンから次のトークンを逐次予測
Transformer
Transformer モデルは、Self-Attention メカニズムを用いてシーケンスデータを処理します

- エンコーダ・デコーダ構造:古典的な seq2seq フレームワークを改良
- 中核的イノベーション:RNN/CNN を完全に排除しアテンション機構に基づく
- 並列処理能力:逐次計算の制限を打破
主要コンポーネント
Encoder
class TransformerEncoder(d2l.Encoder):
def __init__(self, vocab_size, num_hiddens, ...):
self.embedding = nn.Embedding(...) # 単語埋め込み
self.pos_encoding = PositionalEncoding(...) # 位置エンコーディング
self.blks = nn.Sequential(TransformerEncoderBlock(...)) # 層スタック
-
階層構造:
- N 個の同一層を積層(典型値:N=6)
- 各層の構成:
- マルチヘッド・セルフアテンション
- ポジションワイズ FFN
- 残差接続 + レイヤー正規化
-
データ処理フロー:
- 入力埋め込み + 位置エンコーディング →
X = pos_encoding(embedding(X) * sqrt(d_model)) - 層ごとの処理:
for blk in blks: X = blk(X, valid_lens)
- 入力埋め込み + 位置エンコーディング →
Decoder
class TransformerDecoder(d2l.AttentionDecoder):
def __init__(self, vocab_size, num_hiddens, ...):
self.blks = nn.Sequential(TransformerDecoderBlock(...)) # デコーダ層
-
階層構造:
- N 個の同一層を積層(エンコーダと同数)
- 各層の構成:
- マスク付きセルフアテンション
- エンコーダ・デコーダ間アテンション
- ポジションワイズ FFN
- 残差接続 + レイヤー正規化(各サブ層後)
-
重要技術:
- 自己回帰マスク:生成時は過去のトークンのみ参照可能
- 状態キャッシュ:
state[2][self.i]に生成履歴を保存
TransformerBlock
Transformer Block は、Multi-Head AttentionとPosition-Wise Feed-Forward Networksを組み合わせ、TransformerEncoderBlock と TransformerDecoderBlock の両方で使用されるレイヤーです。
class TransformerBlock(nn.Module, ABC):
def __init__(self,
d_model,
n_heads,
attn_dropout,
res_dropout):
super(TransformerBlock, self).__init__()
self.layer_norm = nn.LayerNorm(d_model)
self.self_attn = nn.MultiheadAttention(d_model, n_heads, dropout=attn_dropout)
self.dropout = nn.Dropout(res_dropout)
def forward(self,
query, key, value,
key_padding_mask=None,
attn_mask=True):
"""
From original Multimodal Transformer code,
In the original paper each operation (multi-head attention or FFN) is
post-processed with: `dropout -> add residual -> layer-norm`. In the
tensor2tensor code they suggest that learning is more robust when
preprocessing each layer with layer-norm and postprocessing with:
`dropout -> add residual`. We default to the approach in the paper.
"""
query, key, value = [self.layer_norm(x) for x in (query, key, value)]
mask = self.get_future_mask(query, key) if attn_mask else None
x = self.self_attn(
query, key, value,
key_padding_mask=key_padding_mask,
attn_mask=mask)[0]
return query + self.dropout(x)
@staticmethod
def get_future_mask(query, key=None):
"""
:return: source mask
ex) tensor([[0., -inf, -inf],
[0., 0., -inf],
[0., 0., 0.]])
"""
dim_query = query.shape[0]
dim_key = dim_query if key is None else key.shape[0]
future_mask = torch.ones(dim_query, dim_key, device=query.device)
future_mask = torch.triu(future_mask, diagonal=1).float()
future_mask = future_mask.masked_fill(future_mask == float(1), float('-inf'))
return future_mask
技術的詳細
ポジションワイズ FFN
class PositionWiseFFN(nn.Module):
def __init__(self, ffn_num_hiddens, ffn_num_outputs):
self.dense1 = nn.Linear(...) # 第1全結合層
self.relu = nn.ReLU() # 活性化関数
self.dense2 = nn.Linear(...) # 第2全結合層
- 特徴:
- 全位置で同一の MLP を適用
- 次元調整:入力次元 → 隠れ層 → 出力次元
- 数式表現:
$\text{FFN}(x) = \text{ReLU}(xW_1 + b_1)W_2 + b_2$
残差接続と正規化
class AddNorm(nn.Module):
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X) # 残差接続+正規化
- 設計思想:
- 勾配消失問題の緩和
- 安定した深層学習を実現
- レイヤー正規化 vs バッチ正規化:
- レイヤー正規化:特徴次元で正規化(可変長シーケンスに適応)
- バッチ正規化:バッチ次元で正規化(画像処理向け)
アテンション機構
-
3 種類のアテンション:
- エンコーダ自己注意:Q=K=V=前層エンコーダ出力
- デコーダ自己注意:マスク付き Q=K=V=前層デコーダ出力
- エンコーダ-デコーダ注意:Q=デコーダ状態,K=V=エンコーダ出力
-
マスク実装:
# 訓練時:デコーダが未来情報を見ないようにマスク dec_valid_lens = torch.arange(1, num_steps+1).repeat(batch_size, 1)
主要な革新点
| 技術 | 役割 | 利点 |
|---|---|---|
| マルチヘッドアテンション | 多様な関連性の並列抽出 | 表現力向上 |
| 位置エンコーディング | 順序情報の付与 | RNN 不要の位置認識 |
| 残差接続 | 勾配伝播の最適化 | 深層化可能 |
| レイヤー正規化 | 学習安定化 | 収束速度向上 |
性能優位性
- 並列計算:全トークンを同時処理(RNN の逐次処理を打破)
- 長距離依存:任意の位置間の関連性を直接モデル化
- 拡張性:層の追加で容易にモデル容量増加
- 汎用性:翻訳・要約・生成など多様なタスクに適用